Handling Special PDF Compression Methods
Maarten Van Horenbeeck posted a diary entry (July 2008) explaining how scripts and data are stored in PDF documents (using streams), and demonstrated a Perl script to decompress streams. A couple of months before, I had started developing my pdf-parser tool, and Maarten's diary entry motivated me to continue adding features to pdf-parser.
Extracting and decompressing a stream (for example containing a JavaScript script) is easy with pdf-parser. You select the object that contains the stream (example object 5: -o 5) and you “filter” the content of the stream (-f ). The command is:
pdf-parser.py –o 5 –f sample.pdf
In PDF jargon, streams are compressed using filters. You have all kinds of filters, for example ZLIB DEFLATE, but also lossy compressions like JPEG. pdf-parser supports a couple of filters, but not all, because the implementation of some of them (mostly the lossy ones) differs between vendors and PDF applications.
A recent article published by Virus Bulletin on JavaScript stored inside a lossy stream gave me the opportunity to implement a method I had worked out manually.
The problem: you need to decompress a stream and you have no decompression algorithm.
The solution: you use the PDF application to decompress the stream.
The method: you create a new PDF document with the stream as embedded file, and then save the embedded file using the PDF application.
The detailed method: when you need to decompress a stream for which you have no decompressor (or no decompressor identical to the target application), you create a new PDF document into which you include the object with the stream as an embedded file. PDF documents support embedded files. For example, if you have a PDF document explaining a financial method, you can include a spreadsheet in the PDF document as an embedded file. The embedded file is stored as an object with a stream, and the compression can be any method supported by the PDF application. Crafting this PDF document with embedded file manually requires many manipulations and calculations, and is thus a very good candidate for automation.
Figure: this PDF embeds a file called vbanner2.jpg
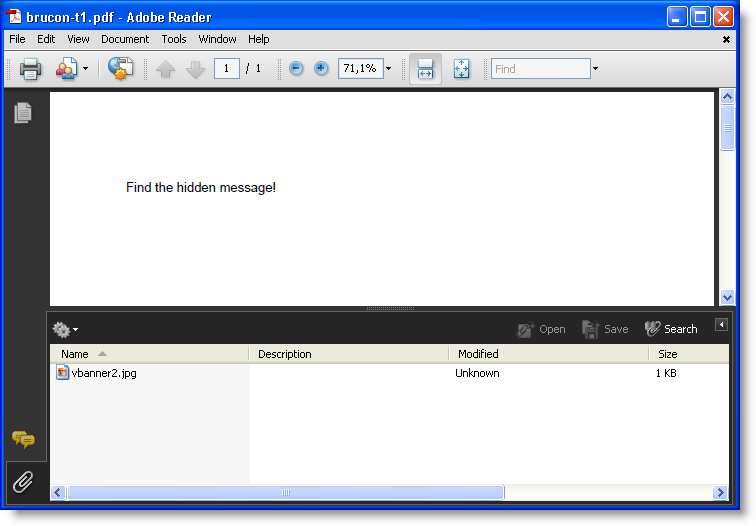
With pdf-parser, you can use this method as follows:
- Create a Python program that generates the PDF document with embedded file. Use pdf-parser like this (in this example, the data stream you want to decompress is in object 5 of PDF file sample.pdf): pdf-parser.py --generateembedded 5 sample.pdf > embedded.py
- Execute the Python program to create the PDF file: embedded.py embedded.pdf
- Open the created PDF file embedded.pdf with the target application (Adobe Reader for the Virus Bulletin example), and save the embedded file to disk
- The saved file contains the decompressed stream
You can find my PDF tools here.
Remark: the generated Python program requires my module mPDF.py, which can also be found on my PDF tools page.
Remark 2: don't use this method when the stream contains an exploit for the decompressor.


Comments