Building a .freq file with Public Domain Data Sources
This diary started out as a frequency analysis of zone files for domains that expire before May 2023. Our intent was to look for frequency of random on all Generic Top-Level Domains (gTLDs). This exercise quickly turned into “create the freq file” for the analysis.
First, we create our .freq file
python3 ./freq.py —create bookmag.freq
The name will make sense as sources are revealed.
My first pass was to download a few famous books from the Gutenberg project (e.g., Sherlock Holmes, a Tall of Two Cities, War and Peace) following the example from [2] [4] Mark. The frequency analysis on that first attempt did not match up to my randomly (not true random as my brain was the random generator, read into that what you will :)).
This got me thinking, can you compile some strange sources and LOTS of data to create a better frequency analysis. More data == better right (well, not always but in this case, maybe)…
This gave me an idea, why not put all of the venerable PHRACK [8] mags in my freq file… To the “Intertubes” BatMan…
Now when you download “ALL” the TGZ files there are a few steps to get them in your new bookman.freq. The first is to uncompress them. And YES, I downloaded them by clicking on them and after about phrack15 or 16 wget -r or curl - something came to mind. Stuck with it and was polite. Thanks Phrack for leaving these rare gems up!
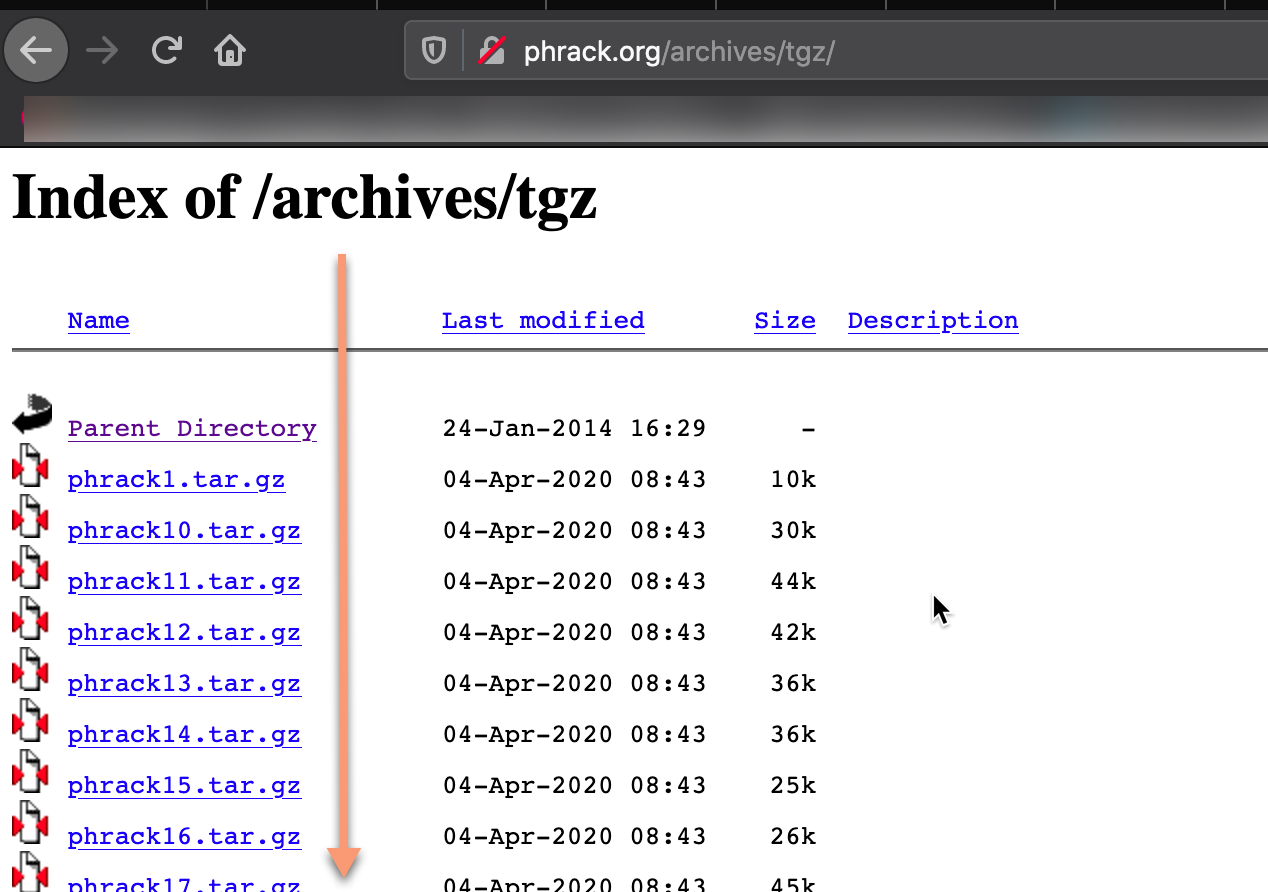
Once you get them unpacked, you can crawl through them pretty easily as noted below:
for fname in `ls ../phrack*/*`
do
echo $fname
python3 ./freq.py --normalfile $fname bookmag.freq
done
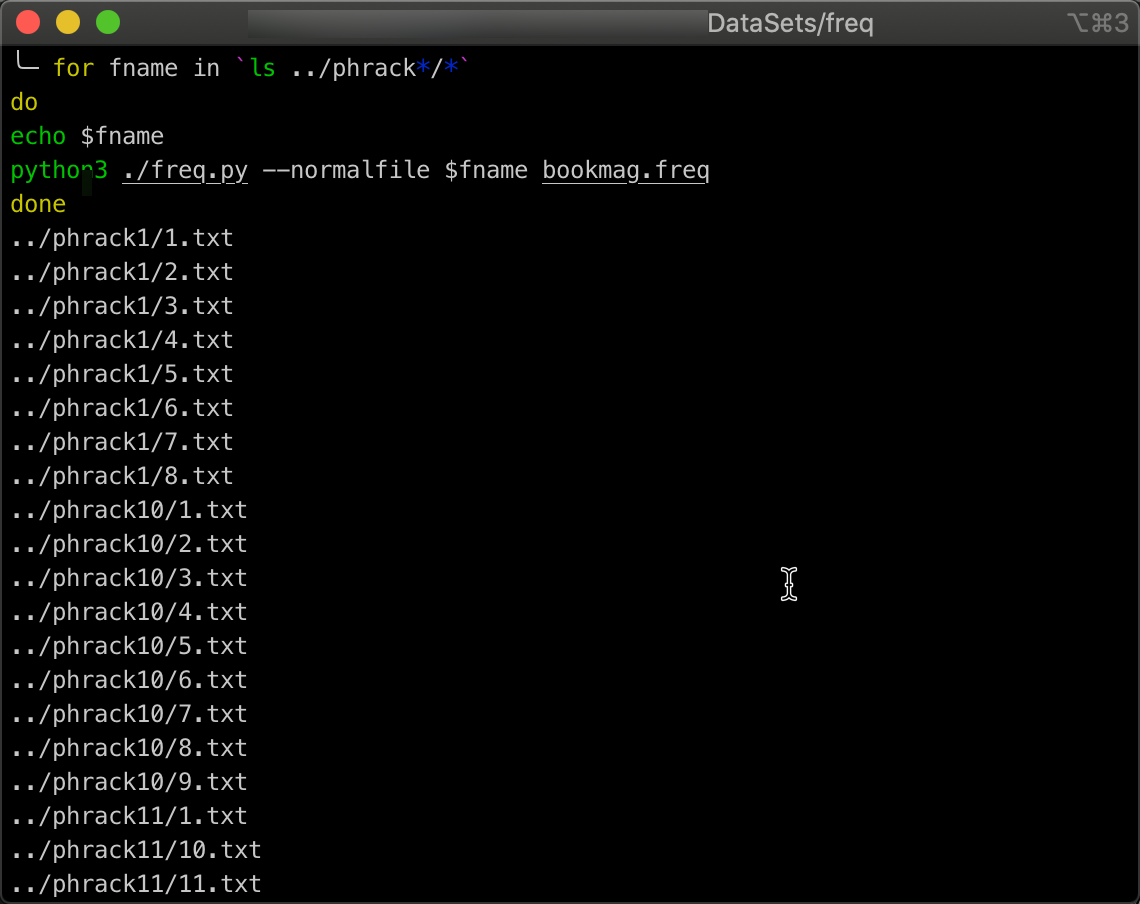
Now are bookmag.freq has all of Phrack as part of its analysis baseline.
Onto the Gutenberg portion cause now the curiosity of “Can I put EVEN MORE literary works in this thing” came to mind.. Go Big or Go <insert somewhere not home here as we are all stuck at home>….
So after locating a DVD ISO of the Gutenberg project (not listed here, but it is easy to find) and going through uncompressing all the ZIP files:
NOTE: Files were transferred from the root of the ISO to a working “RAW” Directory.
for fname in `find ./ "*.ZIP"`
do
unzip $fname -d ../textdocs
done
Here is where zsh barked at me cause it was “TOOOOOO LOOOOOONG”, as apparently there is a limit to looping through an ls.
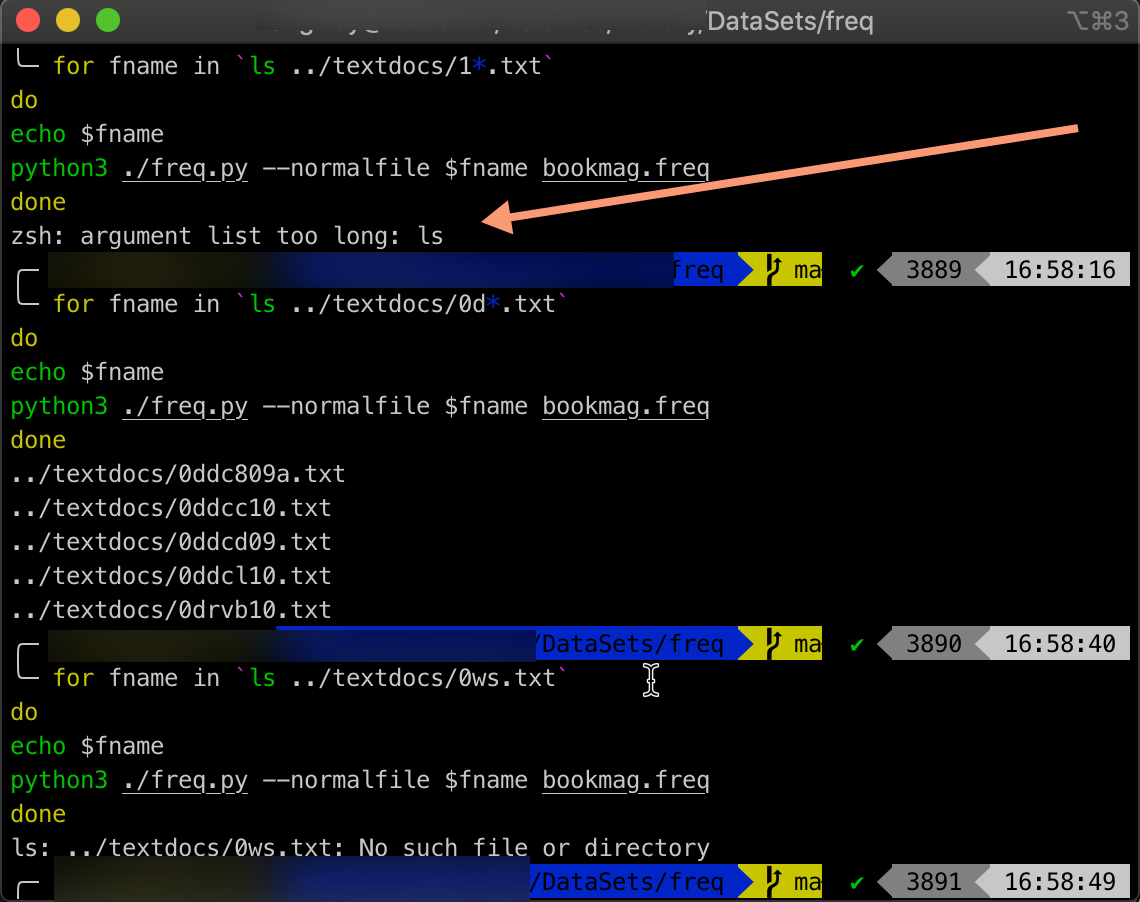
Settled into manually reducing the load on my poor ‘ls’ cmd.
For example changing the ls to ‘0d*.txt’
for fname in `ls ../textdocs/0d*.txt`
do
echo $fname
python3 ./freq.py --normalfile $fname bookmag.freq
done
../textdocs/0ddc809a.txt
../textdocs/0ddcc10.txt
../textdocs/0ddcd09.txt
../textdocs/0ddcl10.txt
../textdocs/0drvb10.txt
Now that we have a robust .freq file we can start testing.
Let us know what sources you decide to use?
References
[1] https://isc.sans.edu/diary/Detecting+Random+-+Finding+Algorithmically+chosen+DNS+names+%28DGA%29/19893
[2] https://github.com/MarkBaggett/freq
[3] http://dev.gutenberg.org/
[4] https://www.youtube.com/watch?v=FpfOzcRpzs8
[5] https://github.com/sans-blue-team/freq.py/blob/master/freq.py
[6] https://wiki.sans.blue/Tools/pdfs/freq.py.pdf
[7] https://isc.sans.edu/diary/freq.py+super+powers%3F/19903
[8] http://phrack.org/


Comments