CFBF Files Strings Analysis
The Office file format that predates the OOXML format, is a binary format based on the CFBF format. I informally call this the ole file format.
It's a binary file format, and is uncompressed (disregarding application specific exceptions, like VBA source code).
That lends itself to strings analysis, as I've wrote about in previous diary entries.
There is a potential problem when you run the strings command on a .doc file, for example. The CFBF file format, is similar to a file system format: it is made up of sectors, and has File Allocation Tables. This means that the data that is contained into streams, is written into sectors. These sectors don't have to be sequential.
If you are looking for URLs for example, you could run the strings command on a .doc file, and grep for string http.
It can happen, that a URL straddles the boundary of 2 sectors: its first part is at the end of sector N, and its last part is at the start of sector N+1. If both sectors are written sequentially into the CFBF file, there is no problem. But if they are not contiguous, the strings command can not extract the complete URL, as it is split into 2 strings that are separated by other data.
I have a couple of solutions to this problem.
The first one I'll cover in this diary entry, is quite simple: my tool oledump.py, a tool to analyze CFBF files, has an option to extract all strings from a stream: -S.
Take this Word document, a .doc file, where I have typed a URL on the first page:
Stream 6 contains the content that I typed:
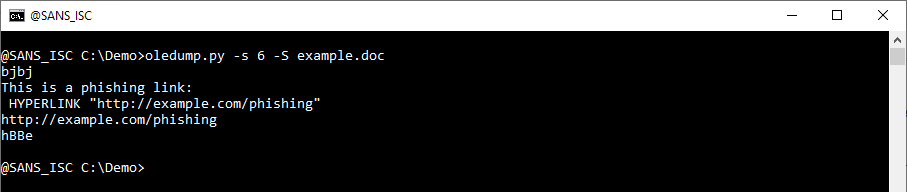
This is for a single stream. Use "-s a" to extract strings from all streams:
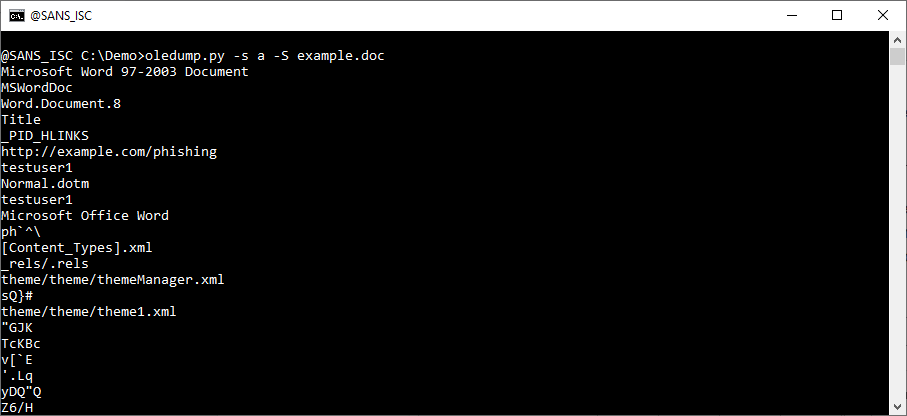
With this last command, you can extract all strings from all streams. And you will not extract strings that are not located in streams, like the names of the streams for example.
You don't have control over oledump's string extraction method, for example, you can not specify a minimum string length (it's minimum 4).
There are other methods where you can do that: that is for another diary entry.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments