
Kernel.org Compromise
Kernel.org announced that it was compromised sometime earlier this month [1]. The compromise was discovered on Aug. 28th. At this point, the assumption is that the attacker obtained valid user credentials, and then escalated privileged to become root. The exact nature of the privilege escalation is not known so far.
The attacker apparently managed to modify the OpenSSH client and server on the system, logging user interactions with the server.
It is very unlikely that kernel source code got altered. The kernel source is verified via SHA-1 cryptographic checksums according to the note on kernel.org. No changes were detected.These hashes exist on other machines as well so if an attacker modifies the hash on the kernel.org server, the change would still be detected.
[an earlier version of this diary stated that the OpenSSH source was modified. This was a misinterpretation of the advisory. Thx Maarten for pointing this out]
[1] http://kernel.org
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
Phishing e-mail to custom e-mail addresses
Geoff wrote in with an interesting phishing sample. The part that it interesting is less the content of the phish, but the e-mail address it was sent to. The content is a standard "ACH Payment Canceled" phish. There are probably a dozen or so that my spam filter dutifully removes each day.
The interesting part: The particular email was send to an address, Geoff only uses for one particular credit rating agency. The "user" part of the e-mail address is the credit rating agencies name.
I assume others here are doing similar tricks to cut down on spam, or at least track where spam is coming from. Many times I see addresses like "user+sans@example.com" in our database. However, in Geoff's case, this would be "sans@example.com", and it is possible that spammers do us company names like that as part of their username dictionary.
Has anybody else seen companyname@example.com addresses used as "To:" addresses in spam? In particular if the company name is a financial institution?
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
11 Comments
Port 8909 Spike
One of our readers noticed a spike in activity recently with regard to port 8909 which can be seen at Dshield. However, we do not have any idea what was causing this. Anyone have any packets or information with regard to this recent trend? Please take a look at your netflows, or other packet captures and lets see if we can answer this question.
Scott Fendley ISC Handler
4 Comments
Cisco Security Advisory - Apache HTTPd DoS
Earlier today, Cisco released a security advisory concerning the Apache HTTPd DoS vulnerability discussed last week (see here).
Cisco is continuing to evaluate the web services embedded in a number of their devices including their Wireless Control System, some of their Video Surveillance and Video Communication Services, and multiple lines of switches which may contain this vulnerability.
In most of these cases, there are workarounds or other forms of mitigation available (such as restricting the IPs or Hosts which can access the service on affected devices). More information is available at http://www.cisco.com/warp/public/707/cisco-sa-20110830-apache.shtml
Scott Fendley ISC Handler
0 Comments
DigiNotar SSL Breach
You probably heard about the breach of the DigiNotar SSL certificate authority by now. In the process, a fraudulent certificate was issued for *.google.com and there is some evidence that the certificate was used to intercept traffic from Iran.
The reason we haven't really written about this so far is that we are somewhat struggling with the advice we should give you.
First of all: The SSL "race to the bottom" CA model is broken. Fraudulent certificates have been issues before, even without breaching a CA's systems.
But what can you do to replace or re-enforce SSL? Lots go over some of the options:
One possibility is to remove the DigiNotar CA from the list of trusted CAs. The problem with this approach is that now legitimate certificates, signed by DigiNotar, will no longer validate. The last thing you want to do IMHO is to get users accustomed to bypassing these warnings. I am not sure how popular DigiNotar is, so maybe it is an option in this case.
Certificate revocation lists are supposed to solve this problem. But they are not always reliable. However, for high profile breaches like this one, expect a browser patch that adds the certificate to a blocklist. Apply the patch as it becomes available.
Use DNSSEC. DNSSEC provides an alternative means to validate that you are connecting to the correct site. It is not perfect either, but somewhat complimentary to SSL and the two together provide some meaningful protect. Sadly, it is not up to you to enable DNSSEC on most sites you connect to.
There are a number of browser plugins that implement reputation systems. I am not sure how well they work. They are pretty new. One that gained some traction is Convergence, which will compare the certificate you received with certificates others received from the same site. How well this works (in particular: false positives...) will yet need to be shown.
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
9 Comments
A Packet Challenge: Help us identify this traffic
Paul wrote in with some "stray packets" he detected on his home firewall against UDP port 10119. The packet appear to come from "all over" and don't look spoofed (various TTLs and IP IDs). All packets have "normal" source ports, and the TTLs suggest that they are all Windows hosts. He is seeing about a dozen packets / minute. So not a DoS, but annoying enough to notice.
Paul uses a dynamic IP address, so the obvious assumption is that this is some for of P2P afterglow from a prior user of this IP address. The question is: What kind of P2P? Is anybody able to identify it? Below you will see a quick excerpt of the traffic (source IP, source port, TTL, IP ID and the payload)
tshark -r 10119.pcap -T fields -e ip.src -e ip.ttl -e ip.id -e data 70.171.209.146 3382 113 0xb692 0000000900000000000000000002f000139c19140000000000 14.198.249.36 2195 109 0x614b 0000000900000000000000000002f0000271e5db0000000000 83.20.76.167 21926 111 0x3f58 0000000900000000000000000002f0000137e7980000000000 74.136.209.108 53251 107 0x419e 0000000900000000000000000002f00001ffb15e0000000000 70.72.59.104 59754 116 0x433a 0000000900000000000000000002f000030f02ae0000000000 46.249.134.251 8741 111 0x2a03 0000000900000000000000000002f0000121f80e0000000000 72.189.39.53 60320 112 0x0ee8 0000000900000000000000000002f000356a1fa80000000000 76.23.146.138 56123 107 0x4859 0000000900000000000000000002f00006eb13260000000000 195.132.68.50 49312 108 0x050f 0000000900000000000000000002f0000109c9e80000000000 67.169.138.216 53355 111 0x6aed 0000000900000000000000000002f000034692cd0000000000 174.62.200.217 55644 109 0x35bc 0000000900000000000000000002f000099db30b0000000000 174.58.91.106 60308 110 0x729f 0000000900000000000000000002f000096ee2350000000000 188.193.225.7 51967 99 0x4d14 0000000900000000000000000002f00001163b7f0000000000
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
3 Comments
Internet Worm in the Wild
Well, the word is out. Morto, the latest Internet worm has arrived and clearly has been working itself around for a while.
After reading the write ups available, it would appear for now, that the network flood is the most substantial consequence for any network with infected hosts.
Prevention looks to be easy. I would not suspect any of our readers to fall victim to this worm, as it appears to take advantage of systems not complying to best practices. Though that is not a proven fact yet, so stay vigilant.
The Microsoft Malware Prevention Center has a detailed write up on Morto here. [1] Check it out and feel free to send us any samples via the contact form here.
As always give us your comments and provide feedback on what is happening out there.
UPDATE:
Thanks to Don for keeping us up to date. MMPC has a new Morto variant write up. Check it out here. [2]
Keep the intel coming folks. I'll continue to update as more info becomes available.
[1] http://www.microsoft.com/security/portal/Threat/Encyclopedia/Entry.aspx?Name=Worm%3AWin32%2FMorto.A
[2] http://www.microsoft.com/security/portal/Threat/Encyclopedia/Entry.aspx?Name=Worm%3aWin32%2fMorto.gen!A
-Kevin
--
ISC Handler on Duty
3 Comments
Some Hurricane Technology Tips
As we are looking at hurricane Irene taking aim at major population and technology centers on the east coast, here a couple of tech tips:
- Cell phone batteries last longer if you turn off non essential services like 3G, bluetooth, wifi.
- keep a hard copy of important phone numbers handy
- make sure all batteries are charged (including spare batteries you may have)
- electricity and water don't mix. If there is a threat of flooding, you may want to turn off the main breaker of your house (not if it is outside and it is wet / raining)
- hurricanes tend to come along with power outages. If you experience a power outage, disconnect major appliances, in particular sensitive ones like computers. During the recovery phase, irregular power and power spikes are likely (you may want to flip the main breaker)
- power suggest caused by lightning can travel over network cable. Unplug networks, in particular cable/DSL modems or other devices that connect to the "outside"
- in most cases, you will be safer at home in your house then on the road once the storm started. If you want to get out, get out now before it is too late
- to contact others, use SMS vs. voice calls. Most cell phone networks will deal with SMS much better then voice
The Red Cross is operating a site that you can use to leave brief "safe and well" messages : redcross.org/safeandwell . Twitter and Facebook can also be handy to leave quick messages for friends telling them that you are fine.
Security issues and Scams:
- if you evacuate your home, consider taking hard drives with other valuables (but they are not always easy to remove)
- frequently, the need arises to make quick system configuration changes to mitigate the impact of a location that is down. Document them carefully even if you appreciate normal change control.
- compromised social networking accounts could be used to send fake pleas for help (and money)
- only donate to reputable organizations that you know and trust. Don't donate to organizations you never heard about
- disaster movies and pictures are likely going to be used to spread malware
We will move this to a "disaster recovery" section that we are about to built. Let me know if you have additional tips. Also: What is in your "jump bag" of stuff that you would take with you?
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
0 Comments
User Agent 007
Recently, while conducting an audit at a financial services company, I decided to verify their claim that their "desktop build is standardized" and "no other devices are on the network". The network team provided access to a SPAN port on their Internet uplink, where I attached my pen-test workstation to take a look.
$sudo ngrep -qt -W single -s1514 -d eth0 -P~ 'User-Agent:' 'port 80'
"ngrep" works like grep, but on network traffic. Thus, the above command digs through everything on port 80 (http) that the span port provides, and searches for the string "User-Agent:", which commonly contains the "signature" of the web client making the access. A little bit of cleanup was needed to make the output usable:
| sed 's/.*User-Agent/User-Agent/' | sed 's/~.*//' | sed '/^$/d'
This takes care of empty lines, and throws out everything that isn't part of the User-Agent: string. Collect the output into a file for a while, and then tally:
$cat output.txt | sort | uniq -c | sort -rn
And lookie, we ended up with about 80 distinct user agents. In only five minutes of traffic. Well, so far for "standardized desktop build" and "nothing else on the network". Among the user agent strings seen were
User-Agent: Mozilla/4.0 (compatible; Lotus-Notes/6.0; Windows-NT)
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1;.NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; .NET4.0E)
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15 (.NET CLR 3.5.30729)
Hmm, peculiar, some users are surfing with IE7 on Windows XP, while others are using an oooold version of Lotus Notes, and again others are using a vulnerable version of Firefox ??
User-Agent: Apple-iPhone3C1/812.1
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)
User-Agent: BlackBerry9000/5.0.0.822
User-Agent: BlackBerry9700/5.0.0.656
A couple of mobile devices ... with what looks like a Windows7/IE9 system thrown in for good measure. The mobile devices turned out to be most interesting, because unless there is a WiFi gateway hooked into the corporate LAN, these devices usually surf via the mobile phone network, and shouldn't show up in the company's outbound Internet traffic. Guess what we found a couple minutes later ...: a little unauthorized wireless network extension, using WEP and the company name as SSID. Duh...!
And, last but not least, we found some odd ducks that certainly warranted a closer look ..:
User-Agent: core
User-Agent: n1ghtCrawler
User-Agent: curl/7.8.1 (sparc-sun-solaris2.6) libcurl 7.9.6 (OpenSSL 0.9.6c)
User-Agent: Mozilla/4.0 (banzai)
Moral of the story: While your IDS probably alerts on "unusual" User Agent strings, it might nonetheless be a good idea to check out the full set of client applications that you have communicating with the Internet. The "User-Agent" string isn't failsafe, but it's a good start. You never know, you might just uncover a Secret (User) Agent who is busy squirreling away your data.
If you have other clever ways of auditing the user agent strings on your perimeter, please share in the comments below!
7 Comments
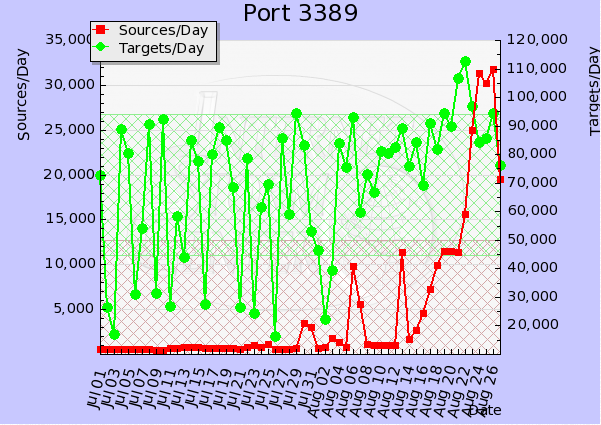
Increased Traffic on Port 3389
A few weeks ago a diary [1] posted by Dr. J pointed out a spike in port 3389 [2] traffic.
Since then the sources have spiked ten fold. This is a key indicator that there is an increase of infected hosts that are looking to exploit open RDP services.
We're interested to know if any of our readers have come across infected hosts that could be contributing to this port knocking out in the wild.
Tell us what you're seeing and please share with us what you can.
[1] http://isc.sans.edu/diary.html?storyid=11299
[2] http://isc.sans.edu/port.html?port=3389
-Kevin Shortt
--
ISC Handler on Duty
1 Comments
Revival of an Unpatched Apache HTTPD DoS
Readers have been writing in and I wanted to get this out to for info and comment. I have not had a chance to test it out myself. It first surfaced in 2007 by Michal Zalewski on bugtraq. [1] It appears due to its lack of sophistication, that it did not get much attention by Apache developers and it has remained unpatched all of this time.
It formally resurfaced last Friday with a proof of concept. A CVE is in draft and a patch is expected in a few days by the Apache team. You can read a discussion about it on the Apache HTTPD dev mailing list. [2] The link provides details on some mitigation measures to be taken. When I get chance I will test and report back.
In the mean time please share your experiences with your fellow readers with a comment.
[1] http://seclists.org/bugtraq/2007/Jan/83
[2] http://marc.info/?l=apache-httpd-dev&m=131418828705324&w=2
-Kevin
--
ISC Handler on Duty
8 Comments
America's Got Telnet !
Sorry for the play on words, but really, we do.
I just finished a security assessment engagement, and the pentest part was one of my shortest in history. Part of the morning procedure for the helpdesk was to login to their "corporate critical infrastructure" gear and verify status and history against a daily checklist. This included all the usual suspects - Backups, critical servers, power, HVAC (Heating, Ventilation, AC), generator, the works. Good so far, right? Keep reading .... The client had a mix of some new and some older UPS Controllers (smart PDUs actually), the older ones only supported telnet and http (no ssh or https). Because this gear was "doing the job", the request to upgrade to the latest version of the gear (which *does* support encryption) was put off until the next budget year (2013).
Part of my internal pentest was to sniff for "the easy stuff" - ftp, telnet and the like (using a man-in-the-middle attack against the user VLAN's default router). Starting with this, especially in smaller environments, is almost a sure thing. I caught a telnet login to the UPS PDU's within 10 minutes of starting the session - and guess what? To keep things easy, they had used the same password for:
UPS PDUs and controllers
Domain Administrator
SQL Server SA
Firewall (vty access and enable)
Routers and Switches (vty access and enable)
So, for the want of 5K worth of upgraded hardware, all of the internal infrastructure was compromised - I had a first draft of the pentest section of the report done before my coffee was finished.

We've done a number of diaries on telnet over the years, notably https://isc.sans.edu/diary.html?storyid=7393, but this message bears repeating, we see telnet over and over (and over), in big companies, small companies, financial, public sector, healthcare, whatever.
Scans for open telnet services on the public internet have their highs and lows, but even the low values remain consistently high ==> http://isc.sans.edu/port.html?port=23
Just re-iterate - compromising telnet is as easy as looking for it. It's not something that should be used in a modern IT group. And yes, Microsoft did us all a great service when they removed it from the default install in Windows 7.
Update 1
I can't believe that I missed this in the initial story, but mainframes and mini computers almost always have telnet enabled. Even if the clients are mostly using ssh or stelnet, telnet is almost always still running as a service on the host, and you'll still find clients connecting to it. In many companies, the mainframe or the p-series or i-series box (or the VMS box in some cases) stores "the crown jewels" - the financial systems and all the customer information. Yet we continue to see these systems as the least protected in many organizations.
(and yes, this graphic is a telnet session)
Important Note - if you plan to run a Man in the Middle (MITM) attack against a busy router, be VERY SURE that you have the horsepower to do this. If you should run out of CPU in this process, you will have ARP Poisoned critical servers in the client's datacenter, potentially making them unreachable by clients. This process can often take up to 4 hours to clear up on it's own (the default ARP timer on many routers and firewalls), depending on the gear. Also, be VERY SURE that you terminate the MITM gracefully when the process is complete (same risk here).
Note 2 - Since 1994, the cert.org team has formally recommended using something other then plain text authentication due to potential network monitoring attacks ( http://www.cert.org/advisories/CA-1994-01.html ). Disabling telnet (and rlogin, and any clear text authentication for admin) is a key recommendation in just about every hardening guide out there. FTP is another nice target - if you have an FTP server, do not allow any interactive user accounts to start an FTP session, as the credentials are sent in the clear. Similarly, do not host or transfer any sensitive information using FTP. If you plan to transfer any sensitive information over a public internet, consider using strong encryption (commonly implemented via FTPS, SFTP, HTTPS or SCP).
===============
Rob VandenBrink Metafore
5 Comments
Disaster Preparedness - Are We Shaken or Stirred?
Yesterday's earthquake (centered in Virginia), along with Monday night's earthquake (centered in Colorado), got me to thinking about disaster preparedness (again).
Lots of IT groups would like to do more in the area of BCP (Business Continuity Planning), but can't get budget due to a management philosophy of "disasters happen elsewhere". For many of my clients in this situation, these earthquakes are nice "wedge" to demonstrate that disasters do in fact happen close to home - everyone had a bit of a pause today when the buildings, and us inside them, swayed back and forth for a minute.
If you have a good DR (Disaster Recovery Plan) at work, now might be a good time to dust it off to make sure everything still works, while this is still fresh in everyone's mind. Make sure that your plan truly reflects the needs of your organization. The IT side of DR is relatively simple - a second location, some servers, replication (often SAN or virtualization based), and you're getting there. Oh - and failing back to the production site is important (and often overlooked) as well.
I've seen DR plans go down in flames, where the IT group comes through 100%, all the backup servers are running, but for one reason or another, the company can't do business. Think things like - where does my main 1-800 telephone number go? How will we ship? How will we receive? There are hundreds of non-IT details that go into a working organization and should go into a good BCP strategy.
Don't neglect DR planning at home as well, there are lots of good references on how to kit your house out for common disasters, but I particularly like the CDC guide on surviving the Zombie Apocalypse ( http://blogs.cdc.gov/publichealthmatters/2011/05/preparedness-101-zombie-apocalypse/ ). If you can survive that, I'm thinking you're good for anything.
The whole DR topic is seeing real interest due to recent events - please, use our comment form and let us know if the recent earthquakes have shaken things up in your organization, if you are now stirred to consider changes in Disaster Preparedness at work or at home?
http://earthquake-report.com/2011/08/22/earthquakes-list-august-23-2011/
http://earthquake-report.com/2011/08/23/very-strong-and-dangerous-earthquake-rattles-virginia/
http://earthquake-report.com/2011/08/22/earthquakes-list-august-22-2011/
http://earthquake-report.com/2011/08/23/unusually-strong-earthquake-in-colorado-new-mexico-united-states/
===============
Rob VandenBrink Metafore
5 Comments
PHP 5.3.8 has been released
This release fixes two issues introduced in the PHP 5.3.7 release:
Fixed bug #55439 (crypt() returns only the salt for MD5)
Reverted a change in timeout handling restoring PHP 5.3.6 behavior, which caused mysqlnd SSL connections to hang (Bug #55283).
All PHP users should note that the PHP 5.2 series is NOT supported anymore. All users are strongly encouraged to upgrade to PHP 5.3.8.
For source downloads please visit the downloads page at
http://php.net/downloads.php
Windows binaries can be found on
http://windows.php.net/download/
Christopher Carboni - Handler On Duty
0 Comments
Surprise?
"The nice thing about being a pessimist," as the old saying goes, "is that every surprise is a good one."
In our industry, it's easy to be pessimistic for any one of a hundred reason that don't need listing here. (Disclaimer - yes, I'm a pessimist)
Whether your glass is half empty, half full, or as one friend recently told me, broken, what is it that surprised you so far this year?
Give us your comments on what surprised you and what you learned from it. Just maybe you can save someone else (less pessimistic) from a painful surprise.
Christopher Carboni - Handler On Duty
6 Comments
Are your tools ready for IPv6? (part 2)
In my previous diary, I started sharing some of my experiences with trying to update my automated malware analysis and honeynet environments to handle IPv6 (the conversation I started with my talk by the same name at SANSFIRE last month). In this diary, I'd like to wrap that up and provide a couple of updates.
So, here are the rest of the tools/categories that I've been looking at/thinking about in my upgrade process.
- Network Management
- SNMP - Back when I was doing a lot more network troubleshooting, one of the primary tools we used to monitor just about everything was HP OpenView which relied on SNMP. While I am not using SNMP in my automated malware analysis environment or (currently) my honeynets, I did start thinking about it. It appears that net-snmp has run fine in IPv6 since 2002 or 2003 and OpenView for at least a couple of years (at least 2009, maybe since 2005). WIN
- FTP/TFTP/SFTP - Again, not something I actually use in these environments, but tools that were used in some previous environments for installing or backing up configurations. There are FTP, TFTP, and SFTP clients and servers for all the OSes that I've looked at that can do IPv6. Whether or not your devices have the appropriate versions installed or not though, who knows. WIN?
- NTP - For log correlation, you want synchronized clocks. If the system can do NTP and IPv6, it can probably do NTP over IPv6. BTW, ff0x::101 are the multicast addresses set aside for the local NTP servers. I'm going to assume WIN
- Logging
- syslog (classic) - okay syslog dates to the 1980s, long before IPv6. You wouldn't really expect the stock syslogd on older OSes to handle IPv6. FAIL
- rsyslog - The current standard on Ubuntu, handles IPv6 just fine. WIN
- syslog-ng - My favorite syslog daemon, also handles IPv6 just fine. WIN
- Kiwi/SNARE - I'm not using any tools to send Windows event logs to a syslog server, so I haven't checked to see how they do with IPv6, but I imagine some of our readers have. ????
- web server/applications - these are pretty much left as an exercise to the reader. ????
- Databases
- Postgresql - One of the things I really like about postgresql is the built-in cidr and inet datatypes for storing IP addresses in databases. As of, at least, v8.2 either type can handle an IPv6 address as well as IPv4. WIN
- MySQL -While it lacks the built-in types that Postgreql has, for IPv4 they provide built-in functions inet_aton() and inet_ntoa() to convert addresses to integers for storage in the database. As of version 5.6.3, MySQL will (does?) have inet6_aton() and inet6_ntoa(). WIN?
- Oracle - It has been over a decade since I was an Oracle DBA, but from what I can tell...not so much. FAIL
- IDS/IPS
- snort/snort-inline - As with the firewalls discussion in the previous diary, I haven't looked at the commercial products lately. if any of our readers can fill me in on how they do, it would be greatly appreciated. The previous setup was based on the Honeynet Project's roo honeywall (the issues with updating roo are worthy of a diary all their own) which was running snort 2.8.something. I am using 2.9.0.5 in the updated setup and it seems to work just fine. I've heard reports of some issues with snort and IPv6, but have not encountered any problems myself. WIN
- Scanning
- nmap - Okay, with the tremendous increase in the size of the target space, linear scanning isn't particularly practical anymore. We will need to figure out more efficient ways to scan. That said, there is still no ability to specify an IPv6 CIDR block as of 5.52.IPv6.beta (from June 2011). FAIL
- fping/fping6 - while fping6 exists and can do many of the things that fping can do on IPv6 addresses. Unfortunately, you cannot specify an IPv6 CIDR block or a range of IPv6 addresses with the -g option. FAIL
- nessus - I honestly haven't looked at vulnerability scanners lately. Can any of our readers help me out here? ????
- Pentest tools
- metasploit - I don't do much pen testing these days either, but when I've needed to use metasploit it has mostly worked for me. WIN?
- Miscellaneous other tools
- netcat - there are a number of netcat versions out there that work with IPv6 just fine. WIN
- p0f - this one wasn't on my list for the SANSFIRE talk because, frankly, it just occurred to me about 1.5 weeks ago. Unfortunately, it doesn't support IPv6 now and seems to no longer be supported. I haven't sent off a request to the author though. FAIL
- prads - As a result of p0f not handling IPv6, I started looking around for tools that could do passive (or active) OS fingerprinting of IPv6 traffic and happened across prads. It look promisiing. Is there anything else out there? WIN
There you have the tools that I've looked at and some that I've just thought about. I'm sure I've missed some tools/categories that are important to some of the rest of you. Please feel free to use the comment section or contact form to let me know what I missed.
Update: Since the previous diary, one of our readers pointed out that a new version of httpry (v0.1.6) has just been released that does handle IPv6. Also, due to some personal issues, I haven't been able to get back to any of my scripts until this week. I've updated the tools in http://handlers.sans.edu/jclausing/ipv6/ to handle type 0, 43, and 60 extension headers (hop-by-hop, routing header, and destination options).
---------------
Jim Clausing, GIAC GSE #26
jclausing --at-- isc [dot] sans (dot) edu
SANS FOR558-Network Forensics coming to central OH in Sep, see http://www.sans.org/mentor/details.php?nid=25749
6 Comments
Logs - The Foundation of Good Security Monitoring
To build a good security monitoring program, logs are critical. They feed almost everything we do in monitoring from event correlation to auditing. We need logs from things such as security tools, network devices, servers, databases and applications in order to have an understanding of what is happening. Any SIEM, analyst, auditor, SSA etc. is only as good as the data available for analysis. Think garbage in and garbage out.
Networks and systems today are growing ever larger and more complex. With that, almost all devices can generate logs and there are many different levels of logging that can be configured for each device. It crucial to ensure you get the right logs from the right devices and at the right level. Without this you can and will miss events of interest. However, getting logs from all devices and systems can lead into thousands of devices sending logs and requiring storage of those logs. How do you know what you are getting and if you even getting the right kinds of logs? Here are some key points to consider when setting up or evaluating your logging infrastructure:
1. Know your budget.
The more important the data, the more money companies are *generally* going to be willing to spend on it. I know money is tight and sadly security is often times the first place they make cuts. However, you can only work within the means of the funding you have available. This is important because the more logs you take in requires a more robust logging infrastructure as well as storage for those logs. You may have to choose smartly about the logs you can process from which devices. Know the budget you have to work with when starting up. For those doing an evaluation, its a good time to see if you need to grow and how much that will cost.
2. Determine the devices you should have logging.
There is no simple answer to that question. Ideally its everything, realistically that won't work. How much storage do you have available? How many messages per second can your infrastructure support? How big are the different logs from the different systems you'll be receiving? You also need to know what you are trying to protect and where it lives. Once you answer those questions, it becomes easier to look at your infrastructure for the key devices/systems that you will need logs from that are there to protect your data or will give you information about what is going on with the network and systems surrounding your data. You want logs coming in that will allow you to paint as complete of a picture as possible.
3. Determine what level of logging is needed and document it.
This should be a group decision. What groups in your organization use the logs to support their various jobs? It is those groups who need to have a say in what that level would be be. It is equally important to document this and the logging level for the different device types for future reference. For example, a Cisco router has eight different logging levels and each of these will provide more granular information resulting in more log entries. If you set the level to debug, you can fill your central log storage up pretty fast if you have alot of devices logging. If you set it to alerts then you may not get the information you want. You can even mix and match the logging levels by having devices that are forward facing have more detailed logging levels and those devices that are more protected farther back in the network having less detailed logging. Remember, that this can be changed if it becomes necessary.
4. Know the log retention policy.
Not only do you have to have enough log storage capacity on your logging infrastructure, but you may also face the requirement of retaining those logs for a specified length of time. If you have a log retention policy (most organizations do) you need to know what it is to ensure you have enough SAN or offline storage available to retain the logs you generate. Just because your logging infrastructure may be able to capture the logs you are generating, doesn't mean that you have the necessary long term storage capabilities to meet the retention capabilities.
5. Monitor your log submissions.
How do you know are still getting the logs you asked for, at the level you want and nothing has changed? This is probably one of the toughest areas and the one most often overlooked My experience has been that people hand folks an SOP with how to send their logs, confirm they are getting logs and then that is it. I have to say this is tough, especially in a large organization where you can have thousands of devices sending you logs. How do you know if anything has changed? How can you afford not to when so much is riding on the logs you get?
6. Plan for the future.
If your network is going to grow, you need to ensure your logging infrastructure can grow with it. This can include many areas such as log servers, appliances, SAN storage, offline storage, capacity of tools that are going to ingest these logs, additional personnel, etc. You need to plan well in advance of when you are going to need to expand.
As you should see by now, your logging team has to have a pulse on everything going on with the network. A logging infrastructure takes a lot of work, but the benefit is worth it. It provides the foundation of your security monitoring and deserves more time than it is often given. If your analysts or auditors check the logs for a specific issue and don't see anything ask yourself if because its not there or could it be because they aren't getting the logs or information they need.
If you any lessons learned or comments for setting up or managing an effective logging infrastructure...please let us know!
10 Comments
When Good Patches go Bad - a DNS tale that didn't start out that way
I recently had a client call me, the issue that day was "the VPN is down". What it turned out to be was that RADIUS would not start, because some other application had port UDP/1645 (one of the common RADIUS ports) open. Since he didn't have RADIUS, no VPN connections could authenticate.
So, standard drill, we ran "netstat -naob", to list out which application was using which port, and found that DNS was using that port. Wait, What, DNS? DNS doesn't use that port, does it? When asked, what port does DNS use, what you'll most often hear is "UDP/53", or more correctly, "TCP/53 and UDP/53", but that is only half the story. When a DNS server makes a request (in recursive lookups for example), it opens an ephemeral port, some port above 1024 as the source, with UDP/53 or TCP/53 as it's destination.
So, ok, that all makes sense, but what was DNS doing, opening that port when the service starts during the server boot-up sequence? The answer to that is, Microsoft saw the act of opening the outbound ports as a performance issue that they should fix. Starting with DNS Server service security update 953230 (MS08-037), DNS now reserves 2500 random UDP ports for outbound communication
What, you say? Random, as in picked randomly, before other services start, without regard for what else is installed on the server Yup. But surely they reserve the UDP ports commonly seen by other apps, or at least UDP ports used by native Microsoft Windows Server services? Nope. The only port that is reserved by default is UDP/3343 - ms-cluster-net - which is as the name implies, used by communications between MS Cluster members.
So, what to do? Luckily, there's a way to reserve the ports used by other applications, so that DNS won't snap them up before other services start. First, go to the DNS server in question, make sure that everything is running, and get the task number that DNS.EXE is currently using:
C: >tasklist | find "dns.exe"
dns.exe 1816 Console 0 19,652 K
In this case, the task number is 1816. Then, get all the open UDP ports that *aren't* using 1816
C: >netstat -nao -p UDP | find /v " 1816"
Active Connections
Proto Local Address Foreign Address State PID
UDP 0.0.0.0:42 *:* 860
UDP 0.0.0.0:135 *:* 816
UDP 0.0.0.0:161 *:* 3416
UDP 0.0.0.0:445 *:* 4
UDP 0.0.0.0:500 *:* 512
UDP 0.0.0.0:1050 *:* 1832
UDP 0.0.0.0:1099 *:* 2536
You may want to edit this list, some of them might be ephemeral ports. If there's any question about what task is using which port, you can hunt them down by running:
taskilst | find "tasknumber"
or, run "netstat -naob" - - i find this a bit less useful since the task information is spread across multiple lines.
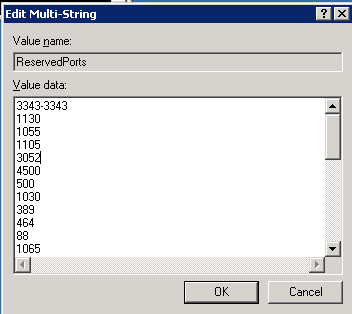
Finally, with a list of ports we want to reserve, we go to the registry with REGEDT32, to HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesTcpipParametersReservedPorts
.png)
Update the value for this entry with the UDP ports that you've decided to reserve:
Finally, back to the original issue, RADIUS now starts and my client's VPN is running. We also added a second RADIUS back in - - the second RADIUS server had been built when the VPN went in, but had since mysteriously disappeared. But that's a whole 'nother story ...
If you've had a patch (recent or way back in the day) "go bad on you", we'd like to hear about it, please use our comment form. Patches with silly design decisions, patches that crashed your server or workstation, patches that were later pulled or re-issued, they're all good stories - - after they're fixed that is !
A final note:
Opening outbound ports in advance is indeed a good way to get a performance boost on DNS, if you have, say 30,000 active users hitting 2 or 3 servers. But since most organizations don't have that user count, a more practical approach to reserving ports would be to simply wait for queries, and not release the outbound ports as outbound requests leave the server, until the count is at the desired number. Maybe reserving ports should wait until the server has been up for some period of time, say 20 minutes, to give all the other system services a chance to start and get their required resources. Another really good thing to do would be to make the port reservation activity an OPTION in the DNS admin GUI, not the DEFAULT.
In Server 2008, the ephemeral port range for reservations is 49152-65535, so the impact of this issue is much less. You can duplicate this behaviour in Server 2003 by adjusting the MaxUserPort registry entry (see the MS documents below for details on this)
References:
http://support.microsoft.com/kb/956188
http://support.microsoft.com/kb/812873
http://support.microsoft.com/kb/832017
===============
Rob VandenBrink
Metafore
11 Comments
Putting all of Your Eggs in One Basket - or How NOT to do Layoffs
The recent story about Jason Cornish, a disgruntled employee of pharmaceutical company Shionogi is getting a lot of attention this week. In a nutshell, he resigned after a dispute with management, and was kept on as a consultant for a few months after.
The story then goes that he logged into the network remotely (ie - VPN'd in using his legitimate credentials), then logged into a "secret vSphere console" (I'd call "foul" on that one - there would be no reason to have a "secret" console - my guess is he used the actual corporate vCenter console or used a direct client against ESX, which you can download from any ESX server, so he had rights there as well) then proceeded to delete a large part of the company infrastructure (88 servers in the story I read). The company was offline for "a number of days", and Jason is now facing charges.
This diary isn't about the particulars of this case, it's much more of a common occurrence than you might think. We'll talk a bit about what to do, a bit about what NOT to do, and most important, we'd love to hear your insights and experiences in this area.
First of all, my perspective ...
Separation of duties is super-critical. Unless you are a very small shop, your network people shouldn't have your windows domain admin account, and vice versa. In a small company this can be a real challenge - if you've only got 1 or two people in IT, we generally see a single password that all the admins have. Separation of duties is simple to do in vmWare vSphere - for instance, you can limit the ability to create or delete servers to the few people who should have that right. If you have web administrators or database administrators who need access to the power button, you can give them that and ONLY that.
Hardening your infrastructure is also important. Everything from Active Directory to vSphere to Linux have a "press the enter key 12 times" default install. Unfortunately, in almost all cases, this leaves you with a single default administrator account on every system, with full access to everything. Hardening hosts will generally work hand-in-hand with separation of duties, in most cases the default / overall administator credentials are left either unused or deleted. In the case of network or virtual infrastructure, you'll often back-end it to an enterprise directory, often Active Directory via LDAP (or preferably LDAPs), Kerberos or RADIUS. This can often be a big help if you have audits integrated into your change control process (to verify who made a particular change, or to track down who made an unauthorized change)
HR processes need to be integrated with IT. This isn't news to most IT folks. They need to know when people are hired to arrange for credentials and hardware. But much more important, IT needs to be involved in termination. They need to collect the gear, revoke passwords and the like, in many cases during the exit interview. When an IT admin is layed off, fired or otherwise terminated, it's often a multi-person effort to change all the passwords - domain admin credentials, passwords for local hosts, virtual infrastructure admins, and the myriad of network devices (routers, switches, firewalls, load balancers, etc). If you've integrated your authentication back to a common directory, this can be a very quick process (delete or disable one account). In this case, a known disgruntled employee was kept on after termination as a consultant with admin rights. You would think that if HR as aware of this, or any corporate manager knew of it for that matter, that common sense would kick in, and the red flags would be going up well before they got to the point of recovering a decimated infrastructure. Yea, I know the proverb about common sense not being so common, but still ....
Backups are important. It's ironic that I'm spelling this out in the diary adjacent to the one on the fallout from the 2003 power outage where we talk about how far we've come in BCP (Business Continuity Planing), but it's worth repeating. Being out for "a number of days" is silly in a virtual environment - it should be *easy* to recover, that's one of the reasons people virtualize. It's very possible, and very often recommended, that all servers in a virtual infrastructure (Hyper-V, XEN, vmWare, KVM whatever), be imaged off to disk each day - the ability and APIs for this are available in all of them. The images are then spooled off to tape, which is a much slower process. This would normally mean that if a server is compromised or in this case deleted, you should be able to recover that server in a matter of minutes (as fast as you can spin the disks). This assumes that you have someone left in the organization that knows how to do this (see the next section).
Don't give away the keys. Organizations need to maintain a core level of technical competancy. This may seem like an odd thing for me to say (I'm a consultant), but you need actual employees of the company who "own" the passwords, and have the skills to do backups, restores, user creation, all those core business IT tasks that are on the checklist of each and every compliance regulation. In a small shop, it's common for IT to give consultants their actual administrative credentials, but it's much more common these days to get named accounts so that activity can be tracked, these accounts are often time limited either for a single day or the duration of the engagement.
I'd very much like to see a discussion on this - what processes do you have in place, or what processes have you seen in other organizations to deal with IT "root level" users - how are they brought on board, how are they controlled day-to-day, and how are things handled as they leave the organization? I'm positive that I've missed things, please help fill in the blanks !
If I'm off-base on any of my recommendations or comments above, by all means let me know that too !
===============
Rob VandenBrink
Metafore
8 Comments
Firefox 3.6.20 Corrects Several Critical Vulnerabilities
Earlier this afternoon, the Mozilla Foundation released an update for their Firefox web browser to correct a number of security issues. Most of the issues corrected in this release are listed at a critical severity. As such, organizations should consider pushing the updated web browser in the near future.
More information concerning the issues is available at www.mozilla.org/security/announce/2011/mfsa2011-30.html
Scott Fendley ISC Handler
0 Comments
Phishing Scam Victim Response
With the start of a new school year right around the corner, there is usually an uptick in phishing scams directed toward Academia. As has been reported many times over the past several years, the number of new faculty and students in Higher Ed, coupled with the limited amount of access controls in place on many systems, makes this an optimal time for the scams to be directed at our campuses.
I am a huge advocate of educating these new members of our community concerning the protection of their user credentials. For my environment, I am actively making the case that a personalized message be sent to each and every individual in our organization to educate (or at least remind) about how we conduct our business involving password changes and the use of credentials in our environment. By in large, many of our phishing scam victims were blissfully unaware of the value to their account credentials to an attacker. Or they just assumed an email claiming to be from the university sent to their university email account must be legit.
A number of years ago Johannes presented 6 Simple Steps to Beat Phishing [http://isc.sans.org/presentations/phishthat.pdf ]. These steps are still very valuable in the effort to limit the exposure. Many organizations have conducted "spear phishing" attacks against their own users as a way to raise security awareness. This type of penetration testing, or ethical hacking, likely does has some impact on the overall security posture of your users but I expect that your mileage may vary based on organizational culture.
Unfortunately, there will always be a small number of users who will fall victim to phishing scams, no matter the amount of training, education or other preventative measures you take.
So what things can you do to recover from a compromised user account. In most of the phishing scams targeting my institution, the intruders were mostly focused on using the account to send out junk mail or other scams.
Junk Email/Scam Attack
- Lock out the user account or reauthorize their ability to authenticate.
- Clean out mail queues to remove any messages which have not been delivered
- Monitor SMTP logs to identify RBLs which may be blocking campus mail servers.
- Reverse any changes to the compromised user account, such as Forwarding Address, Formal Name, signature, Reply-to: and similar.
- Review logs to identify the source IP addresses of the intruders, and identify any other compromised accounts.
- Communicate the abusive behavior to the Net Block in question, and block the IP range if appropriate.
- Review logs to identify any tell-tale addresses which may be used by the intruders to test an account as functional. These addresses are an excellent early warning system to identify accounts which are about to be used in an attack.
- If available, review the content of any phishing scams directed at your organization for phrases, URLs or other details which may be included in spam filters.
- And, obviously, communicate with the user of the account to change their account credentials to prevent unauthorized use.
So what other things would your recommend as part of the recovery of the intrusion? Are there are other steps that need to be followed should the intruder access other resources other than email services?
Scott Fendley ISC Handler
1 Comments
What are the most dangerous web applications and how to secure them?
If you do have a web server, and browse your logs regularly, you will probably find regular probes for various web applications, even some that you don't even use. In many cases, these probes are looking for very common web applications with well known vulnerabilities. Most of the time, the vulnerabilities are old, and a patched version of the application is available. But web applications can be hard to patch and are usually not included in normal patch routines. These web applications are also often customized and the customization makes patching harder. To make things even more complex: It is not always the application itself, but a plugin that is causing the problem.
What I am trying to do here is to assemble a list of the most dangerous web applications. We will use a survey, the 404 project and any other data people may have to rank them. Once these applications are identified, we will try to collect hardening guides to help you run these applications securely.
Please see the survey here http://isc.sans.edu/survey/4 and consider participating to get this project started. The survey will just be one source of data we will be using.
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
0 Comments
8 Years since the Eastern Seaboard Blackout - Has it Been that Long?
The Eastern Seaboard power blackout that occurred in 2003 (started at 4:10 on Aug 14, 2003, with the recovery varying by region) was a milestone in many of our lives. Not only was it full of personal consequences - I can remember my wife calling me in a panic as I was driving home, but it had some severe business and societal impacts, and changed how we view service interruptions in IT.
The blackout forced many businesses to seriously consider what an interruption in basic services could cost the organization, and also to consider how to do business without various services. In short, we now do Disaster Recovery Planning (DRP) and Business Continuity Planning (BCP) a lot more, and a lot more rigorously than we did pre-2003.
The blackout also forced us as a society to consider just how critical our "Critical Infrastructure" is, and how long it had been since it was last looked at closely (post WWII in a lot of cases). It also forced us to look at security in a whole new light - the electrical grid had been built on a "we trust our neighbours" model, which was one of the root problems that made the 2003 event so wide-spread. Most utilities are now a lot more self-contained, or at least aware of the "good fences make good neighbours" design approach these days.
We're a lot more aware now of just how complex our utility infrastructure is now, we've seen first hand what happens when the power goes off, and how complex it was to get the power back on after a widespread hit.
While NERC (North American Electric Reliability Council) has been around since 1968, the power outage was one of the catalysts in re-formulating it as The North American Electric Reliability Corporation, and re-writing the Critical Infrastructure Protection (NERC CIP) regulations in 2006.
Above all, to me the 2003 blackout illustrates just how short our memory is. We had a power hit that affected New York City in 1977 (which I remember), and a much larger Northeast area event back in 1965 (I was 3 then, so before my time). I guess as a society we're a lot like my cat - bad things need to take place a few times at least before it sinks in. Hopefully, now that we've got critical infrastructure standards and particularly security written into regulations and law, it'll stick. Also, now that we've got some momentum in BCP and DR planning, the private sector will follow along.
We'd love to hear your comments, either from your experiences during any of the larger power problems, or how they've affected your organization.

===============
Rob VandenBrink
Metafore
3 Comments
How to find unwanted files on workstations
A few weeks ago I was asked to check every single workstation in the organisation for unwanted files. The types of files I was asked to look for were media files such as music and video, but also torrent files. The main objective was to identify breaches of policy and to allow removal of the unwanted files from the network. I will take you through what I did, which achieved the main objective relatively painlessly. Undoubtedly there better methods than what I'm about to describe and in fact I'm kind of counting on it, so feel free to share how you deal with the challenge. In the mean time this is what I ended up doing.
I obviously didn't really want to visit every machine in the organisation and search the hard drive. Junior has been good lately, so sending him wasn't an option either. The first challenge was to identify the machines currently on the network. Being a windows environment, I considered using dsquery to grab the machine names from AD, but that didn't really work out nicely as the company has computers in all different kinds of OUs. WMIC also had similar limitations and Powershell, well let's just say I'm no Ed, Hal or Tom. I chose the easy option and used nmap. Convenient in this environment as the workstations are quite separate from the servers on their own subnet. The following nmap command does a quick ping sweep and places the results in a grepable output file.
nmap -sP <ip-range>/<mask> -oG <filename>
The the grep output from nmap looks as follows :
Host: aaa.bbb.ccc.20 (machine1.domain.com) Status: Up Host: aaa.bbb.ccc.45 (machine45.domain.com) Status: Up Host: aaa.bbb.ccc.62 (machine62.domain.com) Status: Up … snip ... Host: aaa.bbb.ccc.100 (print01.domain.com) Status: Up Host: aaa.bbb.ccc.101 (print02.domain.com) Status: Up Host: aaa.bbb.ccc.102 (machine102.domain.com) Status: Up Host: aaa.bbb.ccc.115 (machine115.domain.com) Status: Up Host: aaa.bbb.ccc.150 (switch01.domain.com) Status: Up … snip ...
From the list I culled those devices that I was not interested in, e.g. the printers and the switch, before building the commands and creating the batch file.
To do the heavy lifting I used psexec from sysinternals, which allowed me to examine all the machines from one central machine. To create the command and resulting batch file I edited the output file from the nmap.
-
find and replace Host: with PsExec.exe
-
find and replace ( with -w C:\ cmd.exe /c "dir *.mp3 *.avi *.mkv *.mov *torrent* /s /b " > audit-
-
find and replace domain.com with .txt
-
find and replace ) Status: Up with <blank> (i.e. clear it out)
What you end up with should look something like this for each of the entries in the nmap output file.
PsExec.exe aaa.bbb.ccc.45 -w C:\ cmd.exe /c "dir *.mp3 *.avi *.mkv *.mov *torrent*
/s /b " > audit-machine45.txt
Save the file as a .bat file extension, make sure psexec is in the path of the user who will be running the batch file.
What will it do? The command runs PsExec on the IP address, issues the command dir for those extensions listed and outputs the info in a local file called audit-<machinename>.txt. Because we are using a standard dir command you can easily look for any kind of file you like, or partial file names.
Each of the output files will look something like this
C:\Documents and Settings\jdoe\
Desktop\MUSAK\The Police\Greatest Hits\11 - The Police - Spirits In The Material World - Greatest H.mp3 Desktop\MUSAK\The Police\Greatest Hits\12 - The Police - Synchronicity II - Greatest Hits_120113005.mp3 Desktop\MUSAK\The Police\Greatest Hits\13 - The Police - Every Breath You Take - Greatest Hits_1201.mp3 Desktop\MUSAK\The Police\Greatest Hits\14 - The Police - King Of Pain - Greatest Hits_1201130115.mp3 Local Settings\Temporary Internet Files\Content.IE5\HKNBKI0L\novotelrestc[1].mov My Documents\private\vids\SouthPark DVDiv\X 809-814\813 - Cartman's Incredible Gift-AERiAL_mrtwig.net.avi
Someone will need to inspect each of the result files and check to see if the materials are permitted to remain on corporate machines or whether they should be removed. Sometimes the owner wil not be obvious and you might need to examine the machine a little bit closer to determine the owner of the files. Once unwanted files have been identified I usually send the person a policy reminder and a request to have the materials removed. Second/third/nth offences however are passed on to the appropriate area to deal with.
To give you an idea of the effort involved for a site of 400 plus machines (about 325 up when checking).
- Running the nmap - 15 minutes,
- Culling undesirable devices and doing the find and replace commands - 15 minutes.
- Running the batch file - 2 hrs.
- Checking the results - 1 hour,
- Sending the emails - 30 minutes (will obviously depend on how much you find I ended up sending 15).
All in all a reasonably straight forward process and easily adapted to different file types, or file names.
There are some limitations. The user running the psexec command must have privileges in the environment and the machines being checked should be part of the domain. Although you can pass alternate userid and passwords to the command if you want to. You will leave a user profile directory behind on the machine being checked. Only those machines accessible when the batch file is run will be checked, but you could make this part of a login process and write the results file to a network location instead.
Quick and dirty I know, but does the job. How do you find files on your network, including workstations, that should probably not be there?
Cheers
Mark - Shearwater
PS the diary editor seems to strip slashes so if it looks like there should be a backslash, you are probably right.
16 Comments
Telex - A Radical New Approach to Bypass Security
This radical new process was presented at the USENIX Security Symposium last Friday and according to its authors has the potential to turn the entire web into a giant proxy server. "Telex is markedly different from past anticensorship systems, making it easy to distribute and very difficult to detect and block."[1]
This is still a concept rather than a full production system but so far the tests conducted with proof-of-concept software by the researchers had encouraging results. According to the Telex website, "The client secretly marks the connection as a Telex request by inserting a cryptographic tag into the headers. We construct this tag using a mechanism called public-key steganography. This means anyone can tag a connection using only publicly available information, but only the Telex service (using a private key) can recognize that a connection has been tagged."[1]
In order for Telex client to reach a blocklisted site, it needs to use a ISP Telex station that holds a private key that recognize the client Telex connections, decrypt the data and divert the connection to an anti-censorship service such as proxy servers or Tor to access the blocked site. The end result is an encrypted tunnel between the Telex client and an ISP station reaching any sites on the Internet.
A paper published by computer science researchers at The University of Michigan and Waterloo is available here. For updates, source code and an online demonstration, visit their website.[2]
If Telex works as advertized, it has the potential of bypassing current technologies deployed in an organization. How can we prevent a client from accessing this friendly ISP station? Application whitelisting might work, another option might be finding and blocking "friendly ISP" but seems like an impractical proposition. What else do you think could be done to prevent a Telex client from leaving a corporate network to access a Telex ISP station?
[1] https://telex.cc
[2] http://www.scribd.com/doc/60268543/2011-Telex-Anti-Censorship-in-the-Network-Infrastructure
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
3 Comments
FireCAT 2.0 Released
FireCAT: Firefox Catalog of Auditing exTensions version 2.0 has just been released. It contains 90 addons divided in 7 categories further subdivided in 19 sub-categories. A new Protection subcategory (in Misc) has been added to protect Navigation with TrackMeNot, NoScript, cookieSafe, TrackerBlock and Adblock Plus.
The graph showing the list of extensions can be viewed here and mindmap can be downloaded here.
[1] http://www.firecat.fr/news.html
[2] https://addons.mozilla.org/en-US/firefox/addon/trackmenot/
[3] https://addons.mozilla.org/en-US/firefox/addon/noscript/
[4] https://addons.mozilla.org/en-US/firefox/addon/cookiesafe/
[5] https://addons.mozilla.org/en-US/firefox/addon/trackerblock/
[6] https://addons.mozilla.org/en-US/firefox/addon/adblock-plus/
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
Community SANS SEC 503 coming to Ottawa Sep 2011
0 Comments
MoonSols Dumpit released...for free!
The people over at MoonSols have made their amazing one-click memory dump tool Dumpit available for free download.
Dumpit vastly simplifies memory acquisition. Effectively Dumpit combines win32dd and win64dd into one tool and is so simple to use even a non-technical user could do acquisition from a USB key. The dump can then be analyzed using conventional tools such as Redline or Volatility.
For a quick demo of Dumpit, check out the video demo from fellow handler Lenny Zeltser.
-- Rick Wanner - rwanner at isc dot sans dot org - http://namedeplume.blogspot.com/ - Twitter:namedeplume (Protected)
0 Comments
30th Anniversary of the IBM PC - What was your first?
Yesterday was the 30th Anniversary of the release of the IBM PC. It was an interesting walk down memory lane going back and reading some of the reviews of the PC. Over at the ISC this started the discussion of "What was your first computer?" The ISC Handlers vary widely in age, so the answers predictably were quite variable. Oddly enough, although some of us worked with the IBM PC, none of us actually owned one, Timex Sinclair, TRS-80, IBM XT, 286 PC clone, Vic-20, Commodore-64, Amiga and Apple II were some of the answers.
Mine was a TRS80 Model I my Dad bought in about 1978. It was a 4K machine with a cassette tape drive. The first programming language I learned was Z80 assembler, followed shortly by Basic. The first real program I wrote was a bad graphical version of poker dice.
I would love to hear about your first...
-- Rick Wanner - rwanner at isc dot sans dot org - http://namedeplume.blogspot.com/ - Twitter:namedeplume (Protected)
28 Comments
BlackBerry Enterprise Server Critical Update
Blackberry issued a critical update affecting components that process images on a Blackberry Enterprise Server which could allow remote code execution when processing PNG and TIFF image for rendering on their smartphone. These vulnerabilities have been assigned a Common Vulnerability Scoring System (CVSS) of 10.0 (high severity). The following CVEs have been assigned: CVE-2010-1205, CVE-2010-3087, CVE-2010-2595, CVE-2011-0192, CVE-2011-1167
Blackberry recommends applying the fix. "These updates replace the installed image.dll file that the affected components use with an image.dll file that is not affected by the vulnerabilities."[1]
The advisory has a complete list of affected products and is posted here.
[1] http://btsc.webapps.blackberry.com/btsc/search.do?cmd=displayKC&docType=kc&externalId=KB27244
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
0 Comments
Theoretical and Practical Password Entropy
We got a number of submissions pointing to today's XKCD cartoon [1] . I think the cartoon is great, and illustrates a nice dilemma in password security. Yes, I know passwords don't work, but we still all use them and we still have to come up with reasonable passwords.
Even if you are using a password safe tool that comes up with new random passwords for each application and website, you still need to remember the password for the password safe, and there are a few applications (e.g. logging in to your system) that can't be covered by a password safe.
The basic dilemma is that you need to come up with a password that is hard to guess for others but easy enough for you to remember. Most password policies try to enforce a hard to guess password by forcing you to extend the range of characters from which you pick (different case letters, numbers, special characters). However, in real life, this may actually reduce the space of "memorable" passwords, or the total number of possible passwords.
Pass phrases, as suggested by the cartoon, are one solution. But once an attacker knows that you use a pass phrase, the key space is all for sudden limited again. There has been some research showing that a library of 3 word phrases pulled from wikipedia makes a decent dictionary to crack these passwords.
The qualify of a password is usually expressed in "bits of entropy". The "bits of entropy" are calculated by the number of bits it would take to represent all possible passwords. Lets look at some common schemes:
a 4 digit PIN: 10,000 possible passwords, or 13.3 bits (ln2(10,000)=13.3)
12 characters using the full 95 characters ASCII set: 5.4 10^23, or 78.8 bits. (this is the current NIST recommendation)
Pass phrases are harder to evaluate. It depends on the size of the vocabulary of the user, and of course the constraints of grammar. People will likely not choose some random words, but a phrase that makes some sense to them. One model that can be used to obtain a passphrase is called "Diceware", but it assumes random phrases from 6^5 words (7,776).If you consider Diceware's 7,776 words, you would need 6 words to arrive at the same 77.5 bits, close to strength that NIST asks for.
What it all comes down to: How are people actually selecting passwords? People make pretty bad random number generators, in particular if you ask them to remember the result. A good password cracking algorithm takes this into account and tailors the password list based on password requirements and the targets background. For example, for web application pen testing, the simple ruby script "cewl" will create a custom password list from words it finds on the targets website. In past tests, I was easily able to double my password cracking success using this technique if compared to normal dictionaries.
In order to solve this, we need to figure out what passwords people really use. How about asking them for their password and offering them a candy bar in return :). And then there is always another XKCD cartoon for you [2]
[1] http://www.xkcd.org/936/
[2] http://xkcd.com/538/
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
16 Comments
Samba 3.6.0 Released
Samba just released a new version which includes some major enhancements:
- Changes in security default authentication to NTLMv2 with better CIFS/Kerberos support
- SMB2 support is fully functional but by default, is currently deactivated (see release note)
- Overhaul of Spollss code
- ID Mapping has been rewritten
- Endpoint Mapper requires more testing and by default, is currently deactivated (see release note)
- SMB Traffic Analyzer has been added
- A new NFS quota backend has for Linux has been added (based on code already in Solaris/FreeBSD)
A complete list of changes can be viewed here and the new tarball can be downloaded here.
[1] http://samba.org/samba/history/samba-3.6.0.html
[2] http://samba.org/samba/ftp/stable/samba-3.6.0.tar.gz
[3] http://msdn.microsoft.com/en-us/library/cc246482%28v=prot.13%29.aspx
[4] http://holger123.wordpress.com/smb-traffic-analyzer/
[5] http://wiki.samba.org/index.php/Spoolss
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
Community SANS SEC 503 coming to Ottawa Sep 2011
0 Comments
Adobe August 2011 Black Tuesday Overview
Although none of us seems to have seen any warning, Adobe has released 5 bulletins today.
Overview of the August 9th 2011 Adobe Patches.
| # | Affected | Known Exploits | Adobe rating |
|---|---|---|---|
| APSB11-19 | Multiple memory corruption vulnerabilities in the shockwave player allow random code execution. | ||
| Shockwave Player CVE-2010-4308 CVE-2010-4309 CVE-2011-2419 CVE-2011-2420 CVE-2011-2421 CVE-2011-2422 CVE-2011-2423 |
TBD | Critical | |
| APSB11-20 | A memory corruption vulnerability in the Flash media Server (FMS) allows a denial of service. | ||
| Flash Media Server (FMS) CVE-2011-2132 |
TBD | Critical | |
| APSB11-21 | Multiple vulnerabilities in flash player allow random code execution. | ||
| Flash Player CVE-2011-2134 CVE-2011-2135 CVE-2011-2136 CVE-2011-2137 CVE-2011-2138 CVE-2011-2139 CVE-2011-2140 CVE-2011-2414 CVE-2011-2415 CVE-2011-2416 CVE-2011-2417 CVE-2011-2425 |
Adobe claims to not be aware of any exploits in the wild against the vulnerabilities are patched in Flash Player | Critical | |
| APSB11-22 | A memory corruption vulnerability in Photoshop CS5, CS5.1 and earlier allows random code execution. | ||
| Photoshop CVE-2011-2131 |
TBD | Critical | |
| APSB11-23 | A cross site scripting (XSS) vulnerability attack against RoboHelp installations. | ||
| RoboHelp CVE-2011-2133 |
TBD | Important | |
Please note that adobe is at the time of writing inconsistent in the CVE names they fixed (CVE-2010-XXXX vs CVE-2011-XXXX), I've tried to guess the right ones, but we won't know for sure till the CVE databases are up to date.
This is an effort to try to structure the non-microsoft patches more or less in a familiar format on Black Tuesday, depending on the amount of available information available we can have more or less columns. Do let us know what you think of it!
--
Swa Frantzen -- Section 66
3 Comments
Microsoft August 2011 Black Tuesday Overview
Overview of the August 2011 Microsoft patches and their status.
| # | Affected | Contra Indications - KB | Known Exploits | Microsoft rating(**) | ISC rating(*) | |
|---|---|---|---|---|---|---|
| clients | servers | |||||
| MS11-057 | Multiple vulnerabilities in Internet Explorer allow random code execution with the rights of the logged on user and information leaks. Replaces MS11-050. | |||||
| MSIE CVE-2011-1257 CVE-2011-1960 CVE-2011-1961 CVE-2011-1962 CVE-2011-1963 CVE-2011-1964 CVE-2011-2383 CVE-2011-1347 |
KB 2559049 | A for-pay exploit for CVE-2011-1347 is available (the fix for this vulnerability is classified by Microsoft as a functionality upgrade) Public disclosure against CVE-2011-1962 and CVE-2011-2383 are also reported. |
Severity:Critical Exploitability:1 |
Critical | Important | |
| MS11-058 | Multiple vulnerabilities in the DNS server allow random code execution through NAPTR (Naming Authority Pointer) queries against recursive servers and denial of service. Replaces MS09-008 and MS11-046. |
|||||
| DNS server CVE-2011-1966 CVE-2011-1970 |
KB 2562485 |
No publicly known exploits |
Severity:Critical Exploitability:3 |
N/A | Critical | |
| MS11-059 | Windows DAC (Data Access Components) can incorrectly restrict the path used for loading libraries, allowing random code execution (e.g. by opening a excel file on a network share). | |||||
| Windows DAC, exposed through e.g. Excel CVE-2011-1975 |
KB 2560656 |
No publicly known exploits |
Severity:Important Exploitability:1 |
Important | Less Urgent | |
| MS11-060 | Multiple vulnerabilities in Visio allow random code execution with the rights of the logged on user. Replaces MS11-008. |
|||||
| Visio CVE-2011-1972 CVE-2011-1979 |
KB 2560978 | No publicly known exploits | Severity:Important Exploitability:1 |
Critical | Important | |
| MS11-061 | A cross site scripting (XSS) vulnerability in Remote Desktop Web Access. | |||||
| Remote Desktop Web Access CVE-2011-1263 |
KB 2546250 | No publicly known exploits | Severity:Important Exploitability:1 |
Less Urgent | Important | |
| MS11-062 | An input validation vulnerability in the way the NDISTAPI driver validates user mode input before sending it to the windows kernel allows privilege escalation. | |||||
| Remote Access Service (RAS) CVE-2011-1974 |
KB 2566454 | No publicly known exploits | Severity:Important Exploitability:1 |
Important | Less Urgent | |
| MS11-063 | An input validation vulnerability in the Client/Server Runtime SybSystem allows privilege escalation by running arbitrary code in the context of another process. Replaces MS10-069 and MS11-056. |
|||||
| CSRSS CVE-2011-1967 |
KB 2567680 | No publicly known exploits | Severity:Important Exploitability:1 |
Important | Less Urgent | |
| MS11-064 | Vulnerabilities in how windows kernels handle crafted ICMP messages and how Quality of Service (QoS) based on URLs on web hosts handles crafted URLs allow denial of service. Replaces MS10-058. |
|||||
| TCP/IP stack CVE-2011-1871 CVE-2011-1965 |
KB 2563894 | No publicly known exploits | Severity:Important Exploitability:3 |
Important | Important | |
| MS11-065 | A vulnerability in the RDP implementation allows denial of service of the exposed machine. | |||||
| Remote Desktop Protocol (RDP) CVE-2011-1968 |
KB 2570222 | Microsoft reports it is used in targeted exploits. | Severity:Important Exploitability:3 |
Less urgent | Important | |
| MS11-066 | An input validation in the Chart Control allows retrieval of any file within the ASP.NET application. | |||||
| ASP.NET Chart Control CVE-2011-1977 |
KB 2567943 | No publicly known exploits | Severity:Important Exploitability:3 |
N/A | Important | |
| MS11-067 | A cross site scripting (XSS) vulnerability in the Microsoft report viewer control. Replaces MS09-062. |
|||||
| Report Viewer CVE-2011-1976 |
KB 2578230 | No publicly known exploits | Severity:Important Exploitability:3 |
Important | Less Urgent | |
| MS11-068 | Access to meta-data of files (can be through the web and file sharing) can cause a reboot of the windows kernel. Replaces MS10-047. |
|||||
| Windows Kernel CVE-2011-1971 |
KB 2556532 | No publicly known exploits | Severity:Moderate Exploitability:? |
Less Urgent | Less Urgent | |
| MS11-069 | Lack of restricted access to the System.Net.Sockets namespace in the .NET framework allows information leaks and control over network traffic causing Denial of Service or portscanning. Replaces MS11-039. |
|||||
| .NET framework CVE-2011-1978 |
KB 2567951 | No publicly known exploits | Severity:Moderate Exploitability:? |
Important | Important | |
We appreciate updates
US based customers can call Microsoft for free patch related support on 1-866-PCSAFETY
- We use 4 levels:
- PATCH NOW: Typically used where we see immediate danger of exploitation. Typical environments will want to deploy these patches ASAP. Workarounds are typically not accepted by users or are not possible. This rating is often used when typical deployments make it vulnerable and exploits are being used or easy to obtain or make.
- Critical: Anything that needs little to become "interesting" for the dark side. Best approach is to test and deploy ASAP. Workarounds can give more time to test.
- Important: Things where more testing and other measures can help.
- Less Urgent: Typically we expect the impact if left unpatched to be not that big a deal in the short term. Do not forget them however.
- The difference between the client and server rating is based on how you use the affected machine. We take into account the typical client and server deployment in the usage of the machine and the common measures people typically have in place already. Measures we presume are simple best practices for servers such as not using outlook, MSIE, word etc. to do traditional office or leisure work.
- The rating is not a risk analysis as such. It is a rating of importance of the vulnerability and the perceived or even predicted threat for affected systems. The rating does not account for the number of affected systems there are. It is for an affected system in a typical worst-case role.
- Only the organization itself is in a position to do a full risk analysis involving the presence (or lack of) affected systems, the actually implemented measures, the impact on their operation and the value of the assets involved.
- All patches released by a vendor are important enough to have a close look if you use the affected systems. There is little incentive for vendors to publicize patches that do not have some form of risk to them.
(**): The exploitability rating we show is the worst of them all due to the too large number of ratings Microsoft assigns to some of the patches.
--
Swa Frantzen -- Section 66
2 Comments
abuse handling
A number of years ago fellow handler Pedro Bueno created a number of malware challenges. They contained malware that could be analyzed as part of the challenge. This was hosted for years on our "handlers server" at handlers.dshield.org and as those of you who know how to use tools like whois can figure out easily, this server is currently hosted at 1and1, a well known hosting company.
Yesterday, Johannes Ullrich, received following email from the abuse department at 1and1:
Your contract number: [censored]
Your customer ID: [censored]
Our reference: [censored]
Note: Your personal 1&1 contract number and your name certify that this e-mail was sent by 1&1 Internet Inc.
Dear Mr. Johannes Ullrich,
We received an external complaint stating that your 1&1 Server hosts a phishing or malware site. The site is to be found at:
http://handlers.dshield.org/pbueno/malwares-quiz/malware-quiz.exe
This certainly results from a hacking attack to your server. Please proceed as follows to reestablish the security of your 1&1 Server:
1. Immediately delete all content on your 1&1 Server related to the phishing or malware site.
2. Run an exhaustive search for any further foreign content. Hackers will mostly have stored files to grant them future access to your 1&1 Server. Delete those files as well.
3. Secure the leak that permitted the attack. You will find the intrusion point through an analysis of your log files.
4. Please get back to us with a short report on the measures you will have undertaken. Simply reply to this e-mail leaving our reference [censored] in your message.
The following general information on hacking attacks may serve you:
I. Attacks of this sort often occur through insecure PHP-files or outdated modules of popular CMS like Joomla!, Contenido or phpBB. Up-dating your software will considerably increase it's security level.
II. Further intrusion points are compromised passwords, often spied out by a virus installed on your local drive.
TIP: Passwords to the administration section of CMS are also often manipulated during hacking attacks.
III. In most cases hackers upload malicious files to grant them future access to your Server. It therefore is of particular importance to scan your Server for malicious content.
If you should require further information, please simply reply to this e-mail, preserving our reference [censored] in your message.
We appreciate your cooperation and look forward continuing to provide you with safe and secure hosting.
Kind regards,
Abuse Team
--
Abuse Department
1&1 Internet Inc.
Some censoring and some reformatting to increase readability have been done
Well there's not much wrong with that form letter except that it's not a result of getting hacked, but that we placed the stuff there intentionally, without any malicious intent obviously.
So our reply:
Dear Abuse Department:
the sample referenced below is intentionally placed on the site as part of a reverse engineering quiz. It is not the result of an attack.
thx.
was replied to our amazement with:
Your customer number: [censored]
Your contract number: [censored]
Our reference: [censored]
Dear Mr. Johannes Ullrich,
Thank you for getting back to us and the measures you have undertaken.
You contributed considerably to re-establishing the security of your account - thanks a lot!
In case we should receive further alerts, you will promptly be notified. Please stay attentive to the security of your account.
Best regards
Abuse Team
--
Abuse Department
1&1 Internet Inc.
It's most likely another form letter so we'll skip over the content itself, but are they really closing the issue and happy to let us host malware? Even if we have not even removed it? Just because we said it was intentional and not a result of being hacked was enough?
Just to clarify: we probably should have password protected the sample to prevent accidents and/or misunderstandings, and are changing that as we write this.
We often end up being those that report abuse and -well- it's frustrating to see well below par responses to our reports, but if this is how easy they let the bad guys get away with hosting malware, then that's no wonder at all.
While I was running abuse departments at ISPs I've always defended the concept that abuse and sales/support are opposing forces in the company. Abuse chases away bad/unwanted customers and/or cripples the service till they do comply with the relevant policies. Surely you end up with those customers that are victims themselves and those customers deserve all possible attention and help, but the abuse department only works well if it's independent from that support and can be the proverbial stick without having to wield carrots all the time.
--
Swa Frantzen -- Section 66
6 Comments
Ping is Bad (Sometimes)
Ok, maybe ping isn't in and of itself "bad". But 2 or 3 times per week, I hear someone say something like "it must be down, I can't ping it". I have to say, this is a bit of a pet peeve for me - in our modern world of firewalls, it's very likely that ping - ICMP echo requests and ICMP echo replies (ICMP Types 8 and 0), are very likely blocked by one firewall or another in the path between the requester and the server or service being tested.
Even more dangerously, I'll hear "the link / server / network / internet is slow - look at my ping times!". Using Ping as a measure of RTT (Round Trip Time) performance is no longer a good way to go. Many ISPs now depress the priority of ICMP packets, so that they'll transport it, but they'll give priority to "real" traffic like HTTP, HTTPS or SMTP.. Network administrators will often also use PING to measure performance of corporate WANs. This can be *very* misleading, as on most such networks, the protocols deemed important are prioritized at various levels, and protocols such as ICMP that are not defined with a QOS will be transported at the default priority, on a best efforts basis. So using ICMP to measure networks that are used for VOIP (Voice over IP), Video over IP, or any traffic governed by QOS (Quality of Service) can be very misleading.
So for a lot of reasons, PING is simply a bad test in many situations. Either it shows things are down when they're up, or if you are using it as a measure of performance, it's not measuring what you think it's measuring.
What should people do? Well, first, test hosts for up/down status on transports that they will receive and reply with. So a webserver should probably be tested using tcp/80, not icmp echo and echo reply. Similarly, RTT (Round Trip Time) performance of networks should be measured using the protocols that we actually wish to measure. Protocols such as tcp/80 (http), tcp/443 (https), or tcp/445 (Server message block (SMB) over IP (Microsoft-DS)).
How do we do this? Well, there are several tools to test exactly this way. Let's cover a few of them:
HPING3:
HPING3 is an nifty little packet crafter, available for source or sometimes binary install on most linux/*nix distros
Let's test a common internet destination:
robv@robv-desktop:~$ hping3 -p 80 -c 2 -S www.google.ca
HPING www.google.ca (eth0 74.125.115.104): S set, 40 headers + 0 data bytes
len=46 ip=74.125.115.104 ttl=128 id=45928 sport=80 flags=SA seq=0 win=64240 rtt=19.6 ms
len=46 ip=74.125.115.104 ttl=128 id=45929 sport=80 flags=SA seq=1 win=64240 rtt=19.0 ms
--- www.google.ca hping statistic ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 19.0/19.3/19.6 ms
Let's use HPING3 to test a DNS server::
robv@robv-desktop:~# hping3 8.8.8.8 --udp -V -p 53
using eth0, addr: 192.168.169.145, MTU: 1500
HPING 8.8.8.8 (eth0 8.8.8.8): udp mode set, 28 headers + 0 data bytes
^C
--- 8.8.8.8 hping statistic ---
6 packets transmitted, 0 packets received, 100% packet loss
round-trip min/avg/max = 0.0/0.0/0.0 ms
Wait, what happened there? We send udp/53 packets to a DNS server, and didn't get a reply - is it down? Nope, it's not down, it just won't reply unless it gets a properly formatted DNS request. This is common in many UDP services - there isn't a 3 way handshake that we can take advantage of to test up/down status of a service. A packet trace shows us exactly what's going on here (wireshark properly sees this as packets with a DNS destination that are not properly formed DNS packets):

NPING
But what if you're on Windows? NMAP now comes with NPING, a much more flexible echo tool than the traditional PING we've all used for years. Let's test response time to that web server again. I'm using the "-q" option to reduce the output of the command.
C: >nping --tcp -p 80 -q www.google.ca
Starting Nping 0.5.51 ( http://nmap.org/nping ) at 2011-07-20 21:04 Eastern Daylight Time
Raw packets sent: 5 (270B) | Rcvd: 8 (368B) | Lost: 0 (0.00%)
Tx time: 4.39000s | Tx bytes/s: 61.50 | Tx pkts/s: 1.14
Rx time: 5.39000s | Rx bytes/s: 68.27 | Rx pkts/s: 1.48
Nping done: 1 IP address pinged in 6.02 seconds
If you need to explicitly set the QOS values in the test, nping will also do that (a handy reference from TOS - DSCP - binary/decimal/hex flag values can be found here ==> http://www.cisco.com/en/US/docs/voice_ip_comm/bts/4.1/command/reference/93PktCbl.pdf )
This example will send UDP packets on port 17000 (a port the RTP range normally used for VOIP calls), the QOS shown here is DSCP EF, or IP precedence FLASH (the 2 QOS values normally assigned to VOIP)
C: >nping --udp -g 17000 -p 17000 -q --tos 184 172.17.1.209
Starting Nping 0.5.51 ( http://nmap.org/nping ) at 2011-08-07 21:54 Eastern Daylight Time
Raw packets sent: 5 (210B) | Rcvd: 0 (0B) | Lost: 5 (100.00%)
Tx time: 4.00100s | Tx bytes/s: 52.49 | Tx pkts/s: 1.25
Rx time: 5.00100s | Rx bytes/s: 0.00 | Rx pkts/s: 0.00
Nping done: 1 IP address pinged in 6.27 seconds
But again, UDP testing problems strike again - note that nping tells us that we have 100% loss on this test. If you do a packet trace, you'll see that the UDP packets are sent, nothing comes back at all - RTP is the right protocol, but the session needs to be negotiated properly before you'll see traffic. The packet trace below shows that there are no return packets.

Cisco Routers IP SLA
As a side note, Cisco routers have an "IP SLA" feature, which will (at the requesting router), send test TCP or UDP packets on any port, and at the other end, reply back on the same protocol. This neatly solves the "how can I measure my WAN QOS?" problem, but what it doesn't do is measure from a real client to a real destination, so this method won't tell you if the webserver in your datacenter is up or not. I won't show an example here, the product documentation does a good job of that.
PYTHON / SCAPY
Finally, what if you don't have these tools, or can't install tools, or can't change the config on your routers? You can do all of this in a short python script using the scapy library (it's python month for me). Note that the overhead of an interpreted language like python will throw off any RTT times, plus, while Scapy is just about the coolest thing ever, it isn't a speed demon (I think the majority of the delay is in Scapy actually). This method is not a good way to test performance, but it will accurately give you up/down status through ACLs.
The nice thing about using python for this is that it is so portable - if you can't install a tool but have python, you can generally throw your own tool together in short order (I put TCPING and UDPING together during a lunch break at SANSFIRE), especially if you can google for similar examples or documentation.
Here's an example TCPING run (note the high echo time due to the overhead of this method - over 1 second ! ):
robv@robv-desktop:~# python tcping.py www.google.ca 80
WARNING: No route found for IPv6 destination :: (no default route?)
RECV 1: IP / TCP 74.125.226.49:www > 192.168.169.145:55154 SA / Padding
RECV 1: IP / TCP 74.125.226.49:www > 192.168.169.145:46152 SA / Padding
RECV 1: IP / TCP 74.125.226.49:www > 192.168.169.145:31151 SA / Padding
RECV 1: IP / TCP 74.125.226.49:www > 192.168.169.145:18754 SA / Padding
RECV 1: IP / TCP 74.125.226.49:www > 192.168.169.145:39331 SA / Padding
Sent 5 packets, received 5 packets. 100.0% hits.
Host is up , approximate RTT is 1002.07920074 ms
I've attached the tcping.py script, as well as a companion udping.py (with the same syntax). They're certainly not the finest python coding you'll ever see, but feel free to review them, and mod them to fit your own requirements if you find them useful. Again, take care when testing UDP services.
I hope this is useful. If you use PING frequently, I hope this sheds some light on why PING might be a good test in some cases, but not in others, and what tools you might use to deal with reachability and QOS issues.
As always, your comments are welcome !
===============
Rob VandenBrink
Metafore
8 Comments
Controlling a Cisco IOS device from an IRC channel
Today is pretty quiet, so I want to share with you a part of my SANSFIRE presentation last july in Washington D.C.
Cisco Embedded Event Manager and TCL programming
The Cisco Embedded Event Manager (EEM) started with IOS 12.3(4)T and 12.0(26)S. Its main goal is to to detect events inside Cisco IOS devices like SNMP traps, Syslog event patterns, config changes, interface counters, timers or routing events. When the requested event is detected, a specific action is performed and it can be programmed as an applet with specific commands sent to the CLI or a TCL program resident in any storage device inside the router.
If you want to trigger a program without happening any event, you just have to choose the "none" event to invoke the program. This technology is very handy to automatize operational procedures inside networking devices
The TCL programming feature was introduced in IOS 12.3(2)T. This scripting language allows to create automated procedures combining commands of the Cisco CLI and the configuration mode. With few exceptions, all commands behave the same as in normal computers and also implements custom extensions to interact with Cisco IOS.
Let's consider the following facts:
- Cisco IOS now has a scripting language
- Cisco devices have storage for the IOS image and the configuration files
- Cisco IOS now supports event manager
What if the programming language is used to perform something nasty within the device that may compromise the entire network?
Compromising the router
To perform such attack, the router must be compromised. The Cisco IOS allows the following remote access methods
- http
- telnet
- https
- Ssh v1 and v2
http and telnet can be compromised by a standard man-in-the-middle (MITM) attack. What about the other protocols that uses cryptography?
- SSL can be easily compromised using ettercap
- The SSHv1 protocol is vulnerable to MITM attacks: Use ettercap or mitm-ssh
- The SSHv2 protocol is also vulnerable: Use mitm-ssh or jmitm2. You can also downgrade the connection to SSHv1 and then perform the MITM attack in the SSHv1 connection part.
Infection Sequence
The IOS device is owned now. For the proof of concept to work, it must be uploaded to any of the storage devices inside the router. Look inside my presentation for the irc.tcl file and upload it to the router. This proof of concept connects the IOS device to an IRC server and accepts commands from a master. Only ping is implemented.
Next step is to trigger the tcl script every time the IOS device boots. The following example assumes the TCL script was loaded to bootflash: device. We can use the Cisco EEM syslog event detector and look for the SYS-5-RESTART string:
event manager applet IRC_CLIENT
event syslog pattern "SYS-5-RESTART"
action 1.0 cli command "enable"
action 1.1 cli command "tclsh bootflash:irc.tcl"
When the IOS device is reloaded, the script is triggered and the IOS device connects to IRC server as CiscoBot. It receives commands from an IRC channel and then executes them inside the device. You can configure the nick who is the master of the Bot.
And the packets got sent:
Remediation
We have not yet seen this type of attack but throughout history it is clear that as new technological innovations emerge, the attackers find new ways to use them to commit their crimes (remember the capabilities of JavaScript in Adobe Reader and a few years ago macro viruses in Microsoft Office?).
Such attacks pose an interesting challenge, because as combined with a mask to the CLI, which will explain in my next diary, can fool the network administrator which won't ever suspect that the IOS device has a malware unless he/she is watching strange events from the network. In this case, the only way to remove malware is from the ROMMON prompt.
You need to be aware of the SSL warnings and SSH host key changes, because it does always happen for a reason. If you don’t pay attention to any of those signs, two seconds after it might be too late.
If you use signed TCL scripts by a trusted source, you can make sure you won't have future surprises inside your network.
Manuel Humberto Santander Peláez
SANS Internet Storm Center - Handler
Twitter: @manuelsantander
Web: http://manuel.santander.name
3 Comments
New Mac Trojan: BASH/QHost.WB
F-Secure blogged about a new Trojan for Mac’s IOSX
http://www.f-secure.com/weblog/archives/00002206.html
It relies on the fact that due to the "dispute" between Adobe and Apple, Apple's latest Mac OS X version "Lion" comes without any flash player, enhancing the odds people do not find it strange to have to install it separately.
This is a DNS changer type malware that modifies the hosts file to redirect google sites to 91.224.160.26. Which appears to be in the British Virgin Islands.
inetnum: 91.224.160.0 - 91.224.161.255
netname: Bergdorf-network
descr: Bergdorf Group Ltd.
country: NL
org: ORG-BGL9-RIPE
admin-c: AJ2256-RIPE
tech-c: AJ2256-RIPE
status: ASSIGNED PI
mnt-by: RIPE-NCC-END-MNT
mnt-lower: RIPE-NCC-END-MNT
mnt-by: AINT-MNT
mnt-routes: AINT-MNT
mnt-domains: AINT-MNT
source: RIPE # Filtered
organisation: ORG-BGL9-RIPE
org-name: Bergdorf Group Ltd.
org-type: other
address: 3A Little Denmark Complex, 147 Main Street, PO Box 4473, Roa
wn, Torola, British Virgin Islands VG1110
admin-c: AJ2256-RIPE
tech-c: AJ2256-RIPE
mnt-ref: AINT-MNT
mnt-by: AINT-MNT
source: RIPE # Filtered
person: Agnes Jouaneau
address: A Little Denmark Complex, 147 Main Street, PO Box 4473
address: Road Town, Torola, VG1110
address: British Virgin Islands
phone: +44 20 81333030
fax-no: +44 20 81333030
abuse-mailbox: abuse@bergdorf-group.com
nic-hdl: AJ2256-RIPE
mnt-by: aint-mnt
source: RIPE # Filtered
% Information related to '91.224.160.0/23AS51430'
route: 91.224.160.0/23
descr: Bergdorf Group Ltd.
origin: AS51430
mnt-by: AINT-MNT
source: RIPE # Filtered
When I asked that server where google was it gave me an interesting response. It is still providing fake replies to dns queries for google.
> lserver 91.224.160.26
Default server: 91.224.160.26
Address: 91.224.160.26#53
> google.com
Server: 91.224.160.26
Address: 91.224.160.26#53
Name: google.com
Address: 91.224.160.26
Watching for upd port 53 packets towards that IP might be a good idea.
UPDATE/CORRECTION:
While the whois information points to the British Virgin Islands a traceroute gave me a very different answer.
Tracing route to 91.224.160.26 over a maximum of 30 hops
1 75 ms <1 ms <1 ms 10.1.195.3
<SNIP>
14 236 ms 147 ms 138 ms Open-Peering-Amsterdam.Te3-3.ar7.AMS2.gblx.net [208.50.237.194]
15 350 ms 139 ms 138 ms jt.altushost.com [217.170.19.60]
16 138 ms 142 ms 142 ms 91.224.160.26
1 Comments
Common Web Attacks. A quick 404 project update
We are now collecting for about a week now, and I think it is time to give everybody a quick update on the project. Thanks to all the submissions so far. We do have some initial results, just not enough to automate the reports quite yet. But there are now clients for perl, python and ASP! (thanks to the contributors)
Some of the most common scans target:
- Word Press. We do have a good number of reports joing for wp-login.php.
- PHPMyAdmin (/phpmyadmin/scripts/setup.php )
- MediaWiki/Wiki (but these hits only come from a few submitters, may not be statistically significant yet)
And some frequently requested files that are likely not an attack:
- robots.txt - search engines will look for it. You should have the file to control well behaved search engines. Just don't use it to list secret / restricted pages ;-)
- apple-touch-icon files (there are a number of different once for different resolutions). This is just like a "favicon", but used by Apple's IOs devices. With them being more and more popular, you may want to set one up.
- crossdomain.xml - this file is used by flash and Silverlight to communicate your cross domain policies. We have talked about the file before. It is a good idea to have an empty one that restricts access (this is the default for up to date flash players)
Please keep the reports coming and please install the "client code" on your error page if you haven't yet. Once you installed it, you can verify if your submissions are working after logging in and projecting to the 404 report page.
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
5 Comments
Are your tools ready for IPv6? (part 1)
For those of you that weren't at SANSFIRE 2 weeks ago, this was the title of the talk I gave there. At the time, I said I wanted to start a dialog with our readers, so this evening, I'd like to start that. At the IPv6 summit just before SANSFIRE, I heard IPv6 referred to as "Y2K without the hard deadline" and, in some ways, I have to say I agree with that. I've spent the last few months looking at my automated malware analysis environment and the honeypots/honeynets that I am responsible for at the day job and working on updating them to handle IPv6 traffic. In some cases, I will need some hardware upgrades before I can continue too far down that road (old boxes that happily run XP SP2 with 256MB of memory aren't nearly as happy when you try to throw Win7 on them). In the meantime, I started looking at the tools that I use and whether or not they can handle IPv6. I have broken the tools down into a couple of categories (that seem useful to me). Then I looked at the tools that I am currently using, or have used in the (recent) pass to accomplish these tasks and examined them to see how they fared with regard to IPv6. I wasn't sure when I began this process, what I would find. I guess I was, mostly, pleasantly surprised that most of the tools could handle IPv6 to some degree, at least, if I updated to the current version. I knew that most of the tools/scripts that I had written didn't handle IPv6 and in several cases, I have done a first cut at adding IPv6 support (the links to the updated tools are at the bottom of this diary). They still need more work, especially with respect to handling optional extension headers (hop-by-hop, routing, destination, etc.). I expect to finish the clean up of those in the next few weeks. There are too many tools that I looked at to cover in one diary, but let me look a a few of them now and I'll continue with the rest of them during my next shift.
- Infrastructure
- RHEL4 - yes, I know this isn't the current version of RedHat, but it was the corporate standard when the malware environment was first set up, so that is what I was using. Unfortunately, it has some significant shortcomings w.r.t. IPv6, mostly around ip6tables which I'll get to below, so I rate this one a FAIL
- XP SP2- yes, again, not the current version, but worked well with the old hardware. I know it is possible to do IPv6 with XP, but I haven't bothered to look at what it actually takes, we decided that this was a good excuse to upgrade, too, especially since many enterprises are moving to Win7 as the desktop of choice (skipping over Vista), FAIL?
- Ubuntu 10.10 - This is the OS, I use for a lot of my throw away VMs and was the Linux distro I used to get my feet wet with IPv6, so this one goes down as a WIN
- Win7 - handles IPv6 quite nicely out of the box, so we'll be updating the honeypots and client machines to it in the near future, WIN
- Network Monitoring
- tcpdump - works just fine (though keep in mind that the 'ip' and 'ip6' BPF filters examine the layer2 frame for the type of layer 3 traffic, so ip != ip6), WIN
- wireshark/tshark - also handle IPv6 just fine, WIN
- ipaudit - this is an old tool that I had been using to generate a 'flow' summary from the pcap, this one has not been actively maintained for a number of years and does not, handle IPv6, FAIL
- argus - given the failure of ipaudit, I looked at some of the other tools I was already using to see if they could fill the gap and argus works great as long as you are using at least version 3.0, WIN
- ngrep - unfortunately, though I love this tool, it doesn't handle IPv6 at all. It doesn't look like it is being actively supported anymore, though I will send in a bug report to the sourceforge group. If I get the time, I may look at providing the patch myself. FAIL
- pngrep.pl - I had already written a 'sort of ngrep workalike' in Perl because I needed to be able to print out something other than dots for the non-ASCII stuff in the packets. This is one of the ones that I've updated to be able to do some IPv6, but still need to put some more work into. WIN
- dnsdump.pl - Another of my scripts that pulls out just the DNS traffic and gives it to me in a PSV file. This is another that I updated, but still needs some work. WIN
- httpry - this is a nice tool that finds HTTP traffic on any port and can summarize it. I was disappointed to discover that it doesn't handle IPv6. I've sent an e-mail to the author, but haven't heard back yet on whether he plans to support it in the future. If he doesn't, I'll need to find (or write) another tool that does this useful task. FAIL?
- fauxdns.pl/fauxsmtp.pl/smtp-sink - In my paper from 2009, I mentioned that I was using Joe Stewart's faux*.pl scripts for my emulated internet. That is still largely true. Joe doesn't have any intention of supporting these scripts and I frankly haven't put much effort into them yet, but I am using the smtp-sink program from postfix to absorb outbound spam and that handles IPv6 quite nicely, so I guess I rate this as FAIL/FAIL/WIN (but the FAILs are on me)
- netflow tools - this is an area that I haven't really looked into much. I know that netflow v9 can do IPv6, so any tools that can handle v9 netflow can probably handle IPv6 flows. Some of my old standbys though were written in the mid-90s (Mark Verber's flow-tools stuff) and that definitely does not, so ????
- Firewalls
- ip6tables - one of the big issues with RHEL4 was that the kernel was simply too old. Even though there is IPv6 support there, ip6tables was not stateful in older 2.6.x kernels. Rather than try to figure out which RHEL /Fedora/CentOS version would work, I ditched those and used what I knew worked from my trials at home. I went with 10.10 because that was the current Ubuntu version when I started this, I'm sure 11.04 would work just as well (as would 10.04 since it is an LTS release). The one remaining issue with ip6tables is that they have removed the 'nat' table. I don't want to get into any arguments about NAT, I know it isn't supposed to be necessar in IPv6. My problem is that since I'm emulating the entire internet, I was NAT-ing just about everything to my server transparently. I still see a need for that. Fortunately, I've found an ip6tables extension that works via the QUEUE mechanism in user space to put NAT back into ip6tables, so this works for me. WIN-ish
- Checkpoint - It has been a number of years since I was a Checkpoint firewall admin, but I know folks who use continue to use Checkpoint an environments where they are turning up IPv6, so I assume the support is really there (not just marketing hype), but I'll call this one ????
- Cisco ASA - As above, I haven't admined a Cisco firewall in a number of years, so I'll defer to you folks on this one, ????
- Packet Crafting
- hping2/hping3 - probably my favorite tool for quick and dirty packet crafting has long been hping because I could set everything on the command line. Alas, I see postings on mailing lists going back to at least 2003 asking when hping3 would get IPv6 support and it still isn't there. I'll check one more time with hping.org, but I suspect I'll be using another tool when I want to craft IPv6 traffic. FAIL?
- sendip - the other command line tool that I sometimes used was sendip and fortunately, this one does seem to handle IPv6, though I'm not sure I can stack the optional headers, but for the quick and dirty it seems to work. WIN
- scapy - the mother of all packet crafting tools handles IPv6 quite well, perhaps I'll have to give up on my quick and dirty command line stuff and just use scapy for all my packet crafting going forward. WIN
So there you have some of what I was looking at. How about you? In the next installment, I'll look at
- Network Management
- Logging
- Databases
- IDS/IPS
- Scanning
- Pentest Tools
- Miscellaneous other tools
My updated tools (and there will be several more beyond the 2 listed above, to be added over the next couple of weeks) will (I believe) eventually be available via our tools page, but for the moment can be found on my handlers page at http://handlers.sans.edu/jclausing/ipv6/
---------------
Jim Clausing, GIAC GSE #26
jclausing --at-- isc [dot] sans (dot) edu
SANS FOR558-Network Forensics coming to central OH in Sep, see http://www.sans.org/mentor/details.php?nid=25749
4 Comments
IRC traffic on non standard ports
I am always quite fond of IDS signatures that look for results of compromise, versus attack attempts. This may sound a bit fatalistic, as these signatures are only triggered after the attack succeeded, but on the other hand, these alerts are actionable and can be tuned better then some of the attack attempts (most of which don't succeed and don't provide a lot of actionable information).
Today, a reader wrote in with a nice detect of "NICK traffic on a non standard port".
Lets explain IRC a bit: IRC is a simple, text based online chat protocol [1], and it is used frequently to control botnets. To prevent simple port based detection, many malicious IRC servers run on odd ports. But the IRC traffic payload can be quite characteristic and easy to spot.
As the user connects to an IRC server, it will set a nick name. This is done via a "NICK" command. In addition, the USER command is used to set a user name. a USER and a NICK command have to be sent to connect to a server, and they are usually sent one after the other.
NICK something USER something else
The reader's IDS captured a single packet due to this signature. The content (slightly obfuscated) was:
NICK {USA|XPa}abcdefg
USER abcdefg
These random strings with specific prefixes are typical for bot C&C, and finding a string like this would make me almost certainly look a lot closer at this particular system.
[1] http://www.irchelp.org/irchelp/text/rfc1459.txt
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
5 Comments
Malicious Images: What's a QR Code
I just wrote a quick note about the Cisco warranty CD mixup. While writing that, it came to me that currently quite a few of our readers may be visiting Las Vegas for this summers security drink fest. Historically, this has been a time to play various pranks on the audience of these conferences. In the past, fake ATMs, odd wifi networks, weird BGP issues and other tricks were mentioned.
One thing to look out for this year may be QR codes. 25% of internet users are now apparently using mobile devices. Many of them have known vulnerabilities the owner didn't bother to patch yet. At Vegas this week, you may prefer using your mobile device via 3G networks to avoid the notoriously unsafe Wifi networks offered at these conferences.
But there is one problem with mobile devices: The keyboard typically stinks. In particular on cell phones. To help you with that, we have "QR" codes. QR codes are bar codes that encode text and are commonly understood by mobile devices. Take a picture of it, and an app will take you to the encoded URL. Sadly, most people are not all that good in encoding barcode, and have no idea what they are entering. Compare it to handing your phone to a "friend" and telling them to type for you.
These barcodes can link directly to browser exploits, or could include other malicious content to manipulate your phone. If you spot a malicious code, let us know ... most of the applications will tell you what URL they are going to open up before they actually load it (similar to some of the short code URLs).

------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
6 Comments
Cisco shipping malicious warranty CD
Cisco released a somewhat unusual advisory today [1]. instead of talking about a vulnerability in a Cisco product, the advisory warns of a CD shipped by Cisco between December 2010 and August 2011 (= now..).
The CD itself does not include any malware, but documents on the CD, if opened in a browser, may include content from known malicious sites and could have lead to exploitation of the user.
According to Cisco, the site in question is down for some time, and they are not aware of Cisco customers being affected by content from the malicious site. But with all the talk about malicious USB sticks and people focusing counter measures on preventing the use of unauthorized USB sticks, CDs/DVDs certainly should be considered too.
If you are in Vegas this week for Blackhat/Defcosn: Be on the lookup for certified pre-pw0n3d vendor software distributed on USB sticks or CDs. (or QR codes? maybe I should do a diary about that)
[1] http://www.cisco.com/warp/public/707/cisco-sr-20110803-cd.shtml
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
0 Comments
Port 3389 / terminal services scans
Thanks to Pat for pointing out a sharp increase in the number of sources scanning for port 3389 [1].
Port 3389 / TCP is used by Microsoft Terminal Services, and has been a continuing target of attacks. If you have any logs you want to share, please submit them via our contact page . In particular if you observed anything different the last couple days.
[1] https://isc.sans.edu/port.html?port=3389
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
5 Comments
SSH Brute Force attacks
A little while ago I asked for some SSH logs and as per usual people responded with gusto. So first of all thanks to all of those that provided logs, it was very much appreciated. Looking through the data it does look like everything is pretty much the same as usual. Get a userid, guess with password1, password2, password3, etc.
One variation did show. One of the log files showed that instead of the password changing the userid was changed. So pick a password and try it with userid1, userid2, userid3, etc, then pick password2 and rinse lather and repeat. Some of the other log files may have showed the same, but not all log files had userid and passwords available.
A number of the IP addresses showed that they were using the same password list, indicating that either they were being generated by the same tool or might be part of the same bot net. Quite a few IP addresses showed up in different logs submitted.
The most common userids were, not unexpectedly, root, admin, administrator, mysql, oracle, nagios. A few more specific userids do creep in, but most are the standard ones.
So not earth shattering or even mildly surprising, but sometimes it is good to know that things haven't changed, much.
As for the attacking IPs. You can find the unique IP addresses performing SSH attacks here http://www.shearwater.com.au/uploads/files/MH/SSH_attacking_IPs.txt
A number of the logs were provided by the kippo SSH honeypot, which looks like it is well worth running if you want to collect your own info.
Thanks again and if I manage to dig out anything further I'll keep you up to date.
Mark
9 Comments
Metsploit 4 hits the downloads
One of my favourite tools has to be Metasploit and version 4 has been released and is available for download.
Updating an existing instance is a cinch, just run the msfupdate or SVN and you should be good to go. Alternatively you can get fresh install files from the metasploit web site. More info here --> https://community.rapid7.com/community/metasploit/blog/2011/08/01/metasploit-40-released?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+metasploit%2Fblog+%28Metasploit+Blog%29
Enjoy.
Mark
0 Comments


4 Comments