Quickly Investigating Websites with Lookyloo
While we are enjoying our weekend, it's always a good time to learn about new pieces of software that could be added to your toolbox. Security analysts have often to quickly investigate a website for malicious content and it's not always easy to keep a good balance between online or local services. When you submit information to a free online service, they're good chances that data you submitted are logged and probably analysed/re-used, remember nothing is "for free". Lookiloo is a tool developed by CIRCL (the Luxembourg CERT) that helps to have a quick overview of a website by scraping it and displaying a tree of domains calling each other. The name "Lookyloo" comes from the Urban Dictionary[1] and means "People who just come to look". The tool provides a simple web interface to submit a new site to query or to review previous analysis:
And a few seconds later, you get a tree of domains used by this website. Here is an example of a website used to deliver spam:
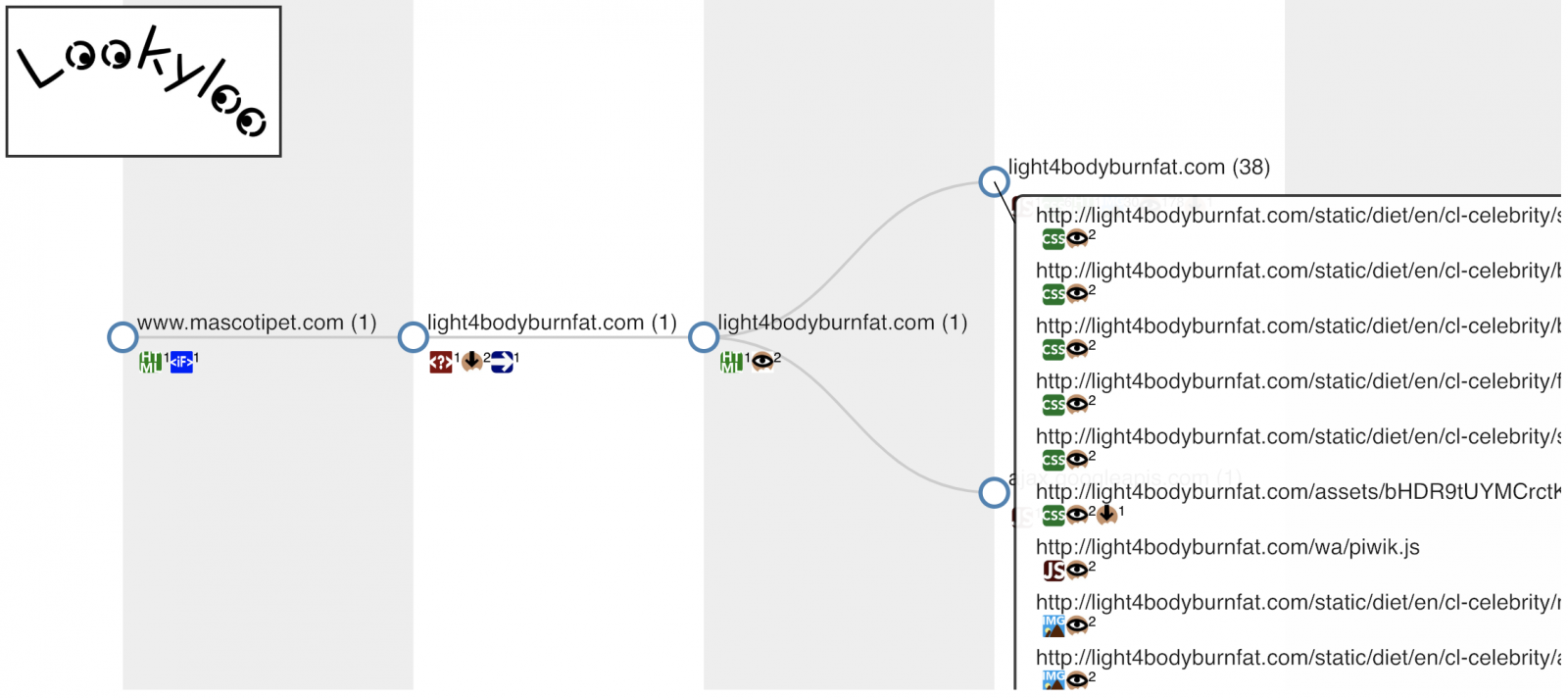
For each domain, you get the following information (if detected):
- Presence of Javascript
- Cookie received
- Cookie read
- Redirect
- Cookie in URL
Some website (particularly news websites) are nice to analyze. Here is the result of scraping cnn.com:

Lookyloo is available on the CIRCL git repository[2]. I recommend you to use the provided docker-compose.yml file to run your own Docker container.
[1] https://www.urbandictionary.com/define.php?term=lookyloo
[2] https://github.com/CIRCL/lookyloo
Xavier Mertens (@xme)
Senior ISC Handler - Freelance Cyber Security Consultant
PGP Key


Comments