
Corrupt BASE64 Strings: Detection and Decoding
My base64dump tool's goals are first to detect BASE64 encoded strings (and other encodings), and second to help with the decoding.
In diary entry "Decoding Corrupt BASE64 Strings" I showed how to detect and decode a corrupt BASE64 string in one single step.
There was a very interesting and detailed reader comment on this diary entry, giving more examples of possible BASE64 corruption and how to deal with them.
In this diary entry, I'm going to cover detection and decoding in more detail.
base64dump.py is a tool that I started to find BASE64 strings inside binary files, like process dumps and PE files. Current versions support much more encodings than BASE64 (like hexadecimal). In large binary files, it can be hard to find BASE64 strings, even with the strings command. So that's the first goal of base64dump: detect the presence of encoded strings.
Let's take a look at a couple of examples. I start with a BASE64 string (aGVsbG8sIHdvcmxk, this decodes to "hello, world") surrounded by binary data (0xE9 bytes). This is my sample binary file containing a small BASE64 string:

base64dump can detect this BASE64 string inside this binary file:

So that the first goal: detection. The second goal is also visualized here: you can see the start of the decoded data.
Now, let's work with a corrupt BASE64 string. I created a sample where I replaced the last character of the BASE64 string with a byte that is not a BASE64 character (0xE9):

base64dump does not detect this corrupt BASE64 string:

The reason is that this string is a sequence of BASE64 characters: 15 characters long, but a valid BASE64 string has a length that is always a multiple of 4. 15 is not a multiple of 4, thus the string is not a valid BASE64 string and base64dump does not detect it.
Since I use my tool base64dump to detect strings like BASE64 strings, I would also want it to detect BASE64 strings with small corruptions, like one or more characters extra or less at the start or end of the string. That's why I added option -p (process) to base64dump:
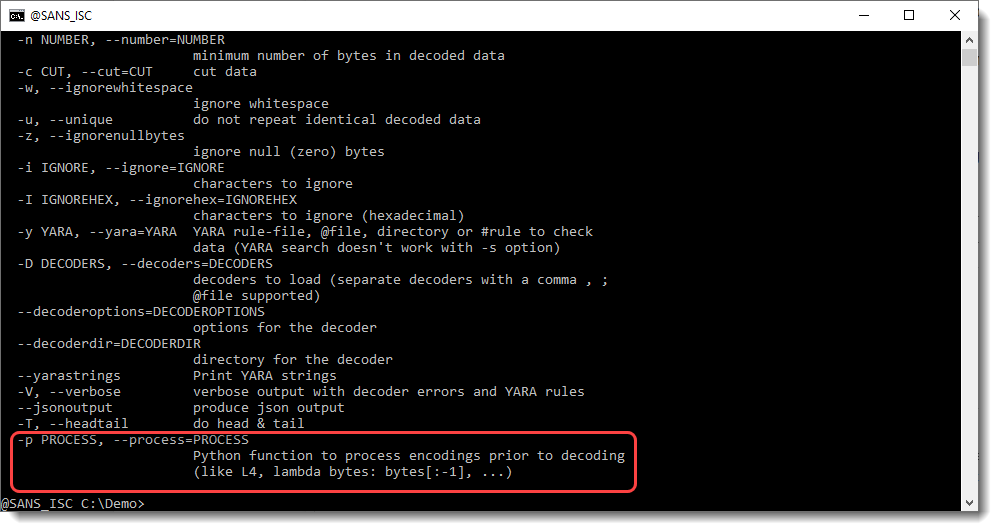
With option -p, one can preprocess strings before they are decoded. This preprocessing is done via a Python function. The value of option -p, is a Python function that will preprocess strings. One of the builtin functions that help with this is L4: L4 is a function that takes a sequence of bytes as input, and returns a truncated sequence so that its lengths is a multiple of 4 (L4 = Length 4). If the input has a length that is a multiple of 4, then the input is returned unchanged.
When I use option -p with Python function L4, the corrupt BASE64 string is detected:

The advantage of this option, is that corrupt strings are also detected. You can see that the Size of the detected string is 12: that's 15 decreased to the nearest multiple of 4 (12). That is the result of function L4. base64dump finds a sequence of BASE64 characters that is 15 characters long, and thus it would be ignored. However, because of preprocessing with function L4, this sequence is truncated to 12 characters, and now it is detected.
That's the first goal: detect encoded data.
Now, in this example, not only was this corrupt BASE64 detected, but it was also decoded into data that is meaningful to us: "hello, wo".
So from this result, we know that there is indeed a BASE64 string inside that binary file, that it is corrupt, for some reason, and that the corruption happened at the end of the string. We know that because we can recognize the decoded value ("hello, ..."), and because we can understand that something is missing at the end of the decoded value.
So now that we have detected (and partially decoded), we can try to "repair" the corrupt string.
First simple test to do for this example, is to add one BASE64 character to the end of the detected BASE64 string. This too can be done with option -p, by using a lambda function that adds character/byte A to the end of its input:

Now we see some extra info: "rl@" was appended to "wo". And this confirms that we are indeed missing a character. If we would be missing 2 characters, then base64dump would not detect this. We would need to add 2 characters. Now, I also recommend to use function L4 when adding characters: this way, you'll allways end up with a valid BASE64 string:

The @ character is added because we added BASE64 character A (this represents 6 zero bits). We could also add a padding character (=):

This was an example with a corrupt character at the end of the BASE64 string.
Let's now do the same with a corrupt character at the beginning of the BASE64 string. Here I replace the first character a with a byte (0xE9):

base64dump does not detect this string:

But it does detect it when we use option -p with function L4:
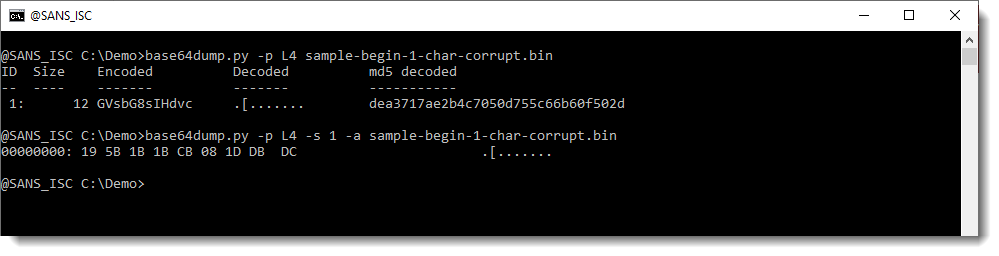
This time, the BASE64 string is detected. But it is not decoded properly: we can not make sense of the decoded value. This is because we are missing one character from the beginning of the BASE64 string: one BASE64 character represents 6 bits, and thus our decoded value is shifted by 6 bits. That's why the decoded value doesn't make sense.
The solution: shift the output by 6 bits. I will show how to bit-shift the output from base64dump with my tool translate, but here I'm going to shift the output by prepending one BASE64 character:
 Now the decoded value makes sense to us: there was indeed one character missing at the beginning of the BASE64 string.
Now the decoded value makes sense to us: there was indeed one character missing at the beginning of the BASE64 string.
If you don't get recognizable output by adding one character, then try adding 2 and 3 characters. If you still don't recognize anything, then either the BASE64 string is not actually encoding anything, or the decoded value needs to be further decoded (decompressed, decrypted, ...). This is something you could try to determine by calculating the entropy of the decoded value, for example.
We looked at BASE64 strings that were corrupt because there was one (or more) character(s) missing from the beginning or ending of the string.
Another possibility, is that there are extra characters, in stead of missing characters.
In this example, I prepend an extra character (x):

When I use base64dump, the BASE64 string is not detected:
 And when I preprocess the input with function L4, the string gets detected:
And when I preprocess the input with function L4, the string gets detected:

But it doesn't decode to anything we recognize. So either this is a fluke, and we are not dealing with a meaningful BASE64 string, or it is not a fluke and we need to do some more processing to try to decode the value.
I could start by adding characters at the beginning until I see something recognizable, but this time, I'll do the opposite and remove characters, by using a Python slice: bytes[1:], e.g. remove the first byte from bytes. Like this:

And again, we see some meaningful data.
If we don't succeed with removing one character, then try 2 and 3 characters.
One can also remove from the end, for example one character: bytes[:-1]
I'll stop now giving examples, and I hope these simple examples illustrate how you can use my base64dump tool with option -p to 1) improve detection and 2) steer decoding.
Of course, this is a trial-and-error process. Usually, you don't know if a BASE64 string was corrupted, and if it is corrupt, how it became corrupt.
Corrupt BASE64 strings are not necessarily caused by an error (like a transmission or decoding error).
They can also be voluntary, to hinder analysis.
Or they can just happen randomly, especially when you are dealing with a binary file like a process memory dump. Inside that dump, it is perfectly possible, for example, that an existing BASE64 string (the one you are looking for, the one that encodes a malicious PowerShell command) is preceded by a 32-bit integer, and that the last byte of that integer is a valid BASE64 character. That character is right before the BASE64 string, and thus it will appear to make the BASE64 string longer by one character: and you end up with a "corrupt" BASE64 string.
In the examples here, we talked about corruption happening at the start or the beginning. It can also happen somewhere inside the BASE64 string, for example in the middle. In that case, you'll end up with 2 (corrupt) BASE64 strings, and you will need to decode them like I explained here, and then put them together.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments