
Decoding Corrupt BASE64 Strings
I was asked to help with the decoding of a BASE64 string that my base64dump.py tool could not handle.
The issue was the following: this particular BASE64 string was corrupt, its length was not a multiple of 4. In BASE64, 64 characters are used to do the encoding: each BASE64 character represents 6 bits. When one byte (8 bits) is encoded, 2 BASE64 characters are needed (6 + 2 bytesbits). To indicate that the last 4 bits of the second BASE64 character should be discarded, 2 padding characters are added (==).
For example, the ASCII character I (8 bits) is represented by 2 BASE64 characters (SQ) followed by 2 padding characters (==). This gives SQ==: 4 bytes long.
When 2 bytes are encoded (16 bits), 3 BASE64 characters are needed (3 * 6 = 18 bits) and 2 bits should be discarded (one padding character =), thus 4 characters are used.
And when 3 bytes are encoded (24 bits), 4 base64 characters are needed (4 * 6 = 24 bits).
Conclusion: valid BASE64 strings have a length that is a multiple of 4.
My tool base64dump.py can handle BASE64 strings that have a length that is not a multiple of 4.
Here is an example. BASE64 string 12345678 is 8 characters long:
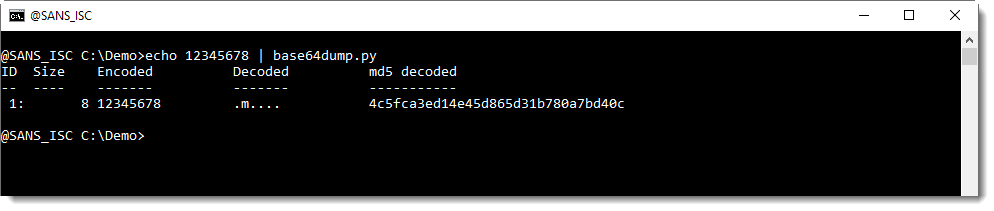

base64dump.py is able to recognize this BASE64 string, and decode it.
Let's add one character, resulting in a BASE64 string with a length that is not a multiple of 4 (length of 9 characters):
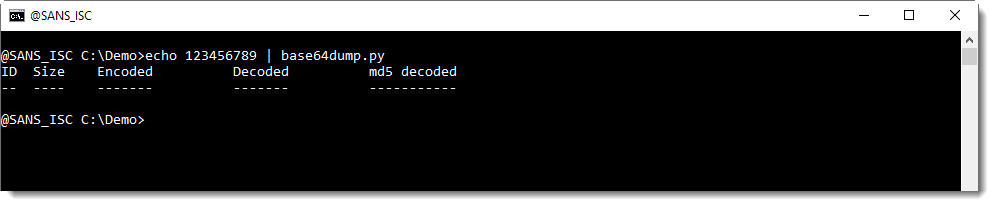
base64dump.py does not recognize this BASE64 string.
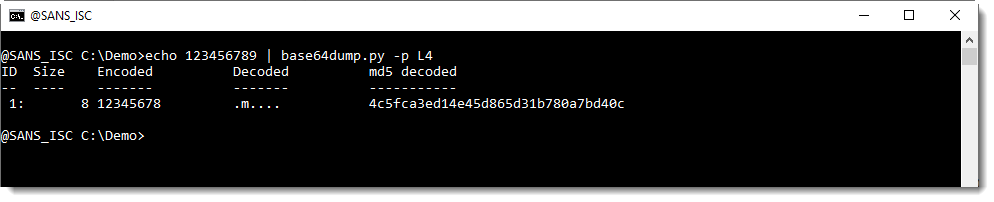
We can help base64dump.py to recognize this string, by using option -p. This option takes a Python function, that will be used to process the detected strings before they are decoded. In this case, we will use Python function L4, a function I defined: it truncates strings to a length that is a multiple of 4.
Using this function L4 with option -p, we can decode the corrupt string:

Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments
Looking a second time, it looks like "4 bytes long" in the third paragraph should be "4 characters long" or "3 bytes long". Looking a third time, "4 bytes long" makes sense if you're talking about the translation of the four 6-bit BASE64 characters to 8-bit characters "on the wire." All the bits, characters, bytes terminology can get confusing. I think pictures work real good here. I just checked, and there is a "Base64" Wikipedia page (with pictures).
Anonymous
Sep 28th 2020
4 years ago
I believe it would be better to add padding rather than to truncate trailing chars that do not fit the modulo 4 condition. Rationale is that some quite common usage of the base64 encoding is on the web where the trailing equal signs are removed in the URL to avoid mis-interpretation of the attribute name.
Common way is to add the padding of "===" and then truncate by for the length to be divisible by 4.
And yes it is not perfect.
For the purpose of malware analysis would be probably better to add "A" (= binary '000000') padding if there is just one trailing character. Then adding "==". And then truncate to make the length divisible by 4.
Instead of "123456789" imagine string "123456789A" ... truncating trailing 2 chars of base64 encoded message would lost whole 1 byte of the input:
$ echo -n "123456789A==" | base64 -d |xxd -a
00000000: d76d f8e7 aefc f4 .m.....
There is actually one interesting topic about this ... some bits of the trailing characters are possibly ignored (or not) by certain implementations of base64, which might give some additional clue about tooling used by the adversaries. For example:
$ echo -n "123456789A==" | base64 -d |xxd -a
00000000: d76d f8e7 aefc f4 .m.....
...
$ echo -n "123456789P==" | base64 -d |xxd -a
00000000: d76d f8e7 aefc f4 .m.....
$ echo -n "123456789Q==" | base64 -d |xxd -a
00000000: d76d f8e7 aefc f5 .m.....
... one could even think of stego-hiding stuff there.
And yes back to original example "123456789" ... having trailing 1 character = 6 bits .. binary '111101' - there is some uncertainty on what the original message could have been. For sure the first (most significant) nibble of the bite was "0xF" (or binary "1111") so we know the byte was bigger than "0xF0". Actually two bits from the other nibble are also known (because base64 '9' is binary '111101' = the other nibble starts with '01') so there is only 4 possible values on what the original binary value could have been: F4, F5, F6 or F7
$ echo -n -e '\xd7\x6d\xf8\xe7\xae\xfc\xf3' | base64
123456788w==
$ echo -n -e '\xd7\x6d\xf8\xe7\xae\xfc\xf4' | base64
123456789A==
$ echo -n -e '\xd7\x6d\xf8\xe7\xae\xfc\xf5' | base64
123456789Q==
$ echo -n -e '\xd7\x6d\xf8\xe7\xae\xfc\xf6' | base64
123456789g==
$ echo -n -e '\xd7\x6d\xf8\xe7\xae\xfc\xf7' | base64
123456789w==
$ echo -n -e '\xd7\x6d\xf8\xe7\xae\xfc\xf8' | base64
12345678+A==
Best regards
Michal Ambroz
Anonymous
Sep 29th 2020
4 years ago
Anonymous
Sep 29th 2020
4 years ago
And what also can happen, is that the valid BASE64 string is prefixed by a BASE64 character, but which is not actually part of the encoded string.
I'll explain this in a diary entry this weekend.
Anonymous
Sep 29th 2020
4 years ago