
PDF documents & URLs
These days, when I receive a suspect PDF document, it's rare that it contains malicious code, but it will rather be a phishing or other social engineering attack. Such PDFs often contain URLs that can be clicked.
URLs can be included in PDF documents using the /URI name. I recently updated my pdfid.py tool to report /URI names too:
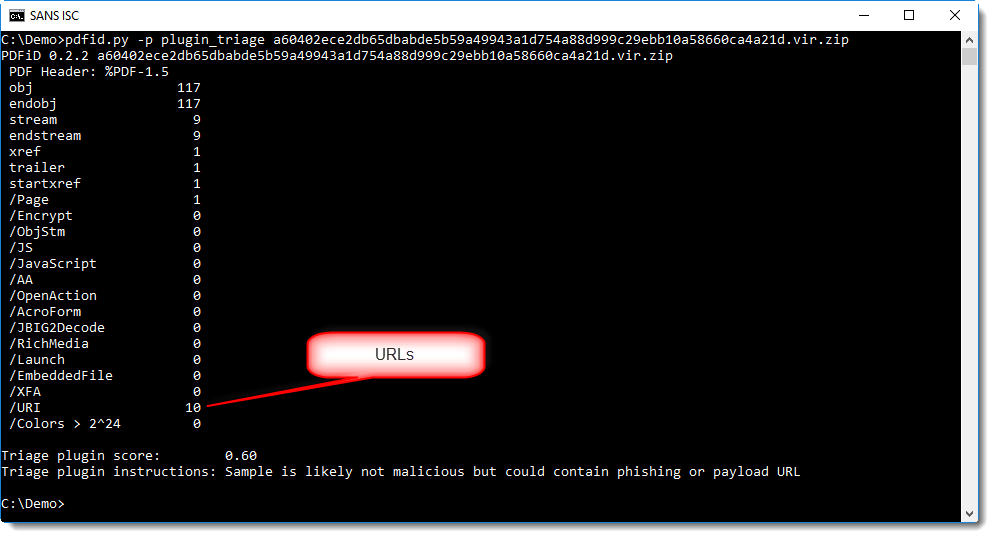
In this screenshot, you can also see the use of a plugin (-p plugin_triage). The purpose of this plugin is to help less experienced malware analyst to triage PDF documents, by assigning a score and providing instructions.
With my pdf-parser.py tool, we can extract the URLs like this:
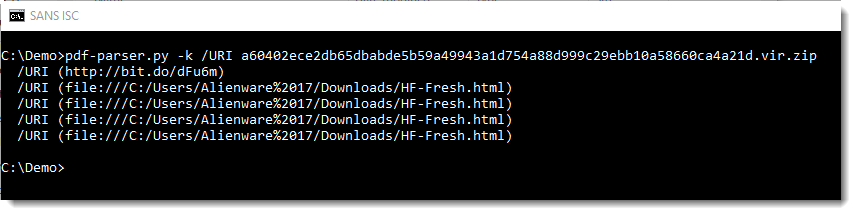
Didier Stevens
Microsoft MVP Consumer Security
blog.DidierStevens.com DidierStevensLabs.com
×
![modal content]()
Diary Archives


Comments
Most of the time this works for me - but I have one PDF with a URL and running the tool shows the following
/URI 18 0 R
Any ideas?
Anonymous
Nov 7th 2017
7 years ago
You can select this object with the following command: pdf-parser.py -o 18 sample.pdf.vir
Anonymous
Nov 7th 2017
7 years ago