
base64dump.py Supported Encodings
I explained to a friend that my tool base64dump.py, despite its name, does support many other encodings than BASE64. For example, it can detect and decode hexadecimal strings too.
To select a different encoding than BASE64, use option -e followed with the name of the encoding, for example: -e hex.
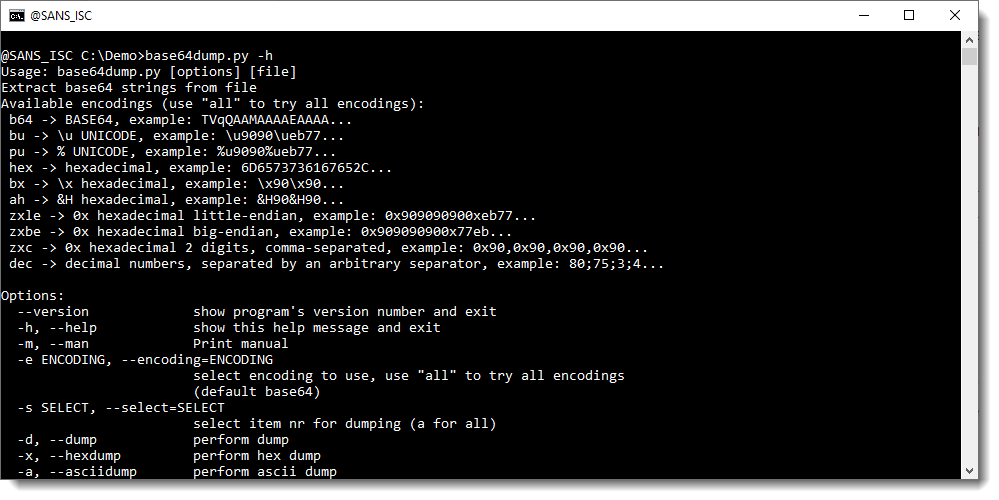
To know which encodings are supported by my tool, use the help (-h) or man (-m) option:
Or use -e ?: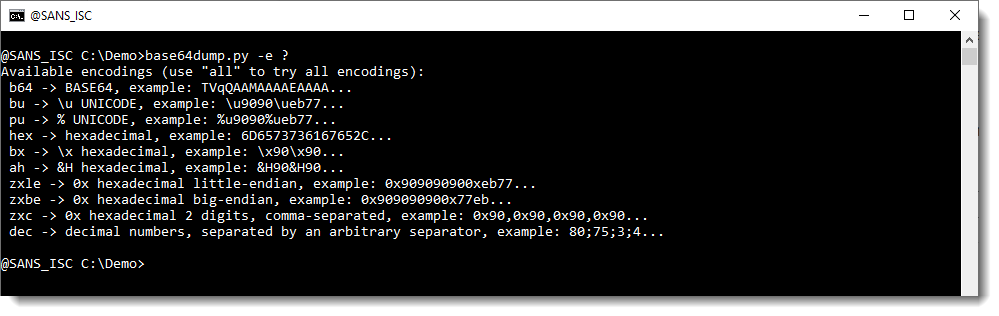
While reviewing the supported encodings, I decided to add support for a new encoding: sequences of decimal numbers, for example found in FireEye's maldocs. In that diary entry, I used my tool numbers-to-string.py to do the decoding, however, in this diary entry I'll show how to use the new version of my tool base64dump.py. Remark that numbers-to-string.py is more versatile to decode sequences of decimal numbers than base64dump.py, as it can take a Python expression to transform each number. If you want to know more about this feature, take a look at diary entry "Small Challenge: A Simple Word Maldoc - Part 2".
Here is method to analyze FireEye's maldocs using base64dump. I use my base64dump.py tool directly to analyze the maldoc (I don't use oledump). I use option "-e all" to let base64dump search for all possible encodings in this binary file (e.g. the maldoc). Since this usually produces a long list of detections (due to very short strings, like numbers), I use option "-n 10" to limit the output. Option "-n 10" specifies that the minimum length of the decoded string is 10 (bytes), shorter strings will not be displayed. Finally, I also use option -u to obtain a list of unique strings (e.g. remove duplicates):
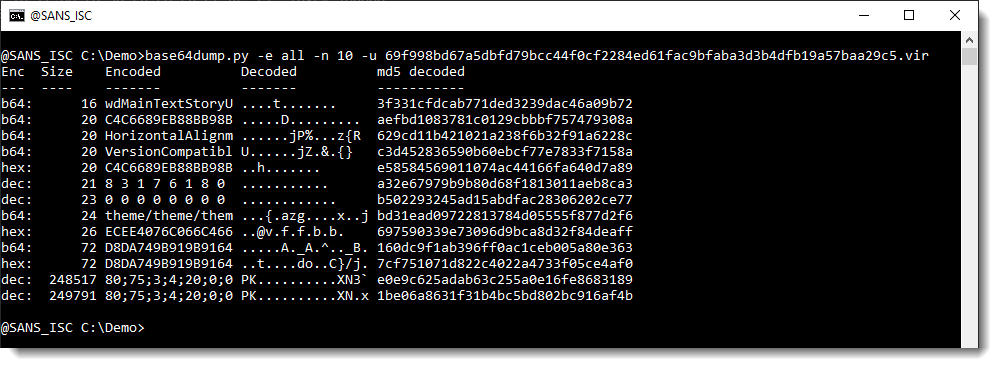
My tool produces a list of all possible strings, sorted by length: the longest strings are listed last. I use this option (-e all) when I don't know what possible strings to expect inside a sample.
With this output, it's easy to see that 2 very long strings were detected (248517 and 249791 bytes long) that match decimal encoding (dec): a long list of decimal numbers separated by a character (; in this sample).
Next I use encoding dec explicitly (-e dec):
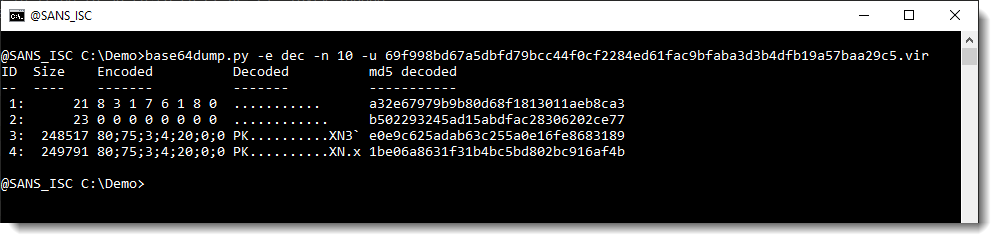
The difference with using option "-e dec" in stead of option "-e all", is that now each string is labelled with an index number allowing easy selection, and that the output is not sorted by string length, but strings appear in the order they are found inside the analyzed file.
In this output (and previous output too), I see that when these 2 long strings are decoded, they start with PK.. : they are probably ZIP files.
Selecting the first long string (-s 3) and piping the decoded, binary data (-d) into my tool zipdump.py confirms that this is a ZIP file:

And the same is true for the second long string (-s 4):

This example shows that for these FireEye's maldocs, one can quickly extract the payload using my new version of base64dump.py.
If you compare this method with the previous method, you'll probably ask yourself why I did use oledump in the previous method, and not in this method.
There are 2 reasons:
1) numbers-to-string.py is a tool that expects text as input (one string per line), and not binary data. I used oledump.py with a plugin in the previous method to produce a list of strings, that can be handled by numbers-to-string.py.
2) in this sample, the streams are not "fragmented". ole files (like .doc, .xls, ...) store data inside streams, and streams are made up of "virtual sectors". It's not a requirement that the sectors that make up a stream are stored consecutively. When that is not the case, streams are "fragmented", and then long strings inside these streams can become fragmented too. oledump.py parses ole files, and handles fragmentation: when a stream is selected for processing, the data is presented sequentially, and fragmentation is not an issue. Would this sample have been fragmented, then the output of base64dump would list many "dec" strings, and it would be necessary to use oledump to select the stream(s), and pipe it into base64dump.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments